- #1 処理時間とレスポンス時間
- #2 バッチ処理とオンライン処理
- #3 バッチ処理を設計するときの注意点(本記事)
- #4 オンライン処理とUXの工夫
- #5 Railsのジョブ管理システムと注意点
- #6 バッチ処理ですぐに使えるノウハウ、まとめ
バッチ処理を設計するうえでの注意点
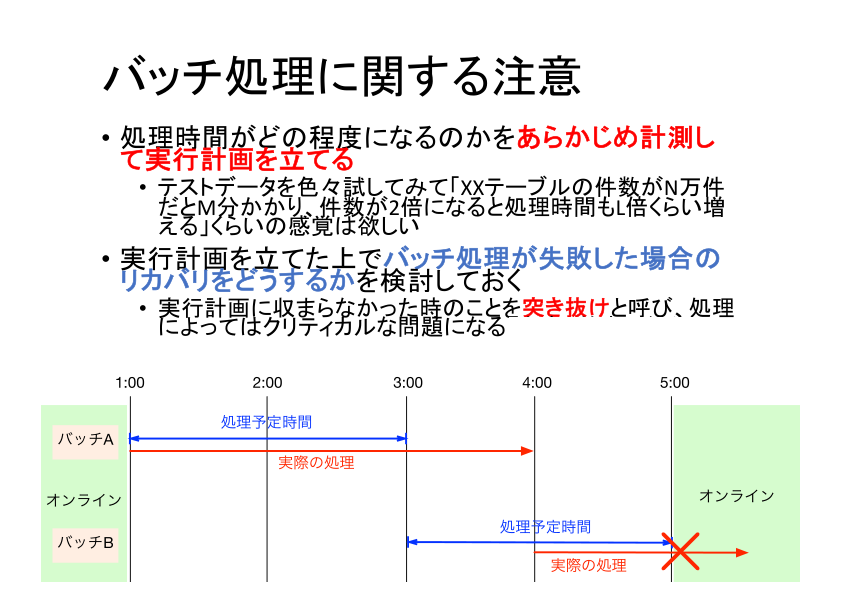
バッチ処理を設計する際は、処理時間がどの程度になるのかを事前に計測・見積し、その結果を元に実行計画を立てるのが重要です。少なくとも、所要時間の見通しもなくバッチ処理を作成するのは危険です。
一般的にはデータ量が増えれば処理時間も増えるので、データ量が増えたときに処理時間がどのように延びるかは予め見積もっておきます。たとえば「データが1万件のときは20分、件数が倍になると処理時間が4倍増える」といったように、データ増加に応じた処理時間を予測できるように計測やベンチマークを事前に実施しておく必要があります。
実行時間計画とは別に、バッチが失敗したときにどのようにリカバリするかも考えておく必要があります。
バッチ処理は溜めておいたデータを一括処理するという性質上、バッチ処理の時点になってはじめて想定外データが見つかってエラーでバッチが止まってしまう、というのはよくある話です。
毎回バッチが一回で成功するはず、という甘い前提で見積もってしまうと、バッチに失敗した場合にリトライする時間を確保できなくなり、いわゆる「突き抜け」と呼ばれる事態に陥る可能性があります。
システム上ミッションクリティカルなバッチ処理については十分に余裕のある実行計画を立て、失敗した場合も想定してリスク管理しておくことが肝要です。
バッチ処理設計のポイント

一度実行したバッチは簡単にやり直すことができないので、慎重に設計しなければなりません。特に外部API(決済サービスなど)と連携したデータがある場合、対向システムの仕様によってはやり直しが不可能なこともあります。
バッチ処理を設計するうえで、一歩引いて考えておきたいポイントがいくつかあります。
1.「システムを停止しないと実行できない作業かどうか」に着目する
トランザクション管理などの難易度は上がりますが、システムを停止しなくても処理を完了できる道があるならば、原則としてオンラインバッチを検討します。マスタデータ洗い替えや、ロック時間がとても長いトランザクション処理など、オンライン処理と並行するのが現実的ではない場合には、システムの計画停止を伴うオフラインバッチで実装することになるでしょう。
2.「処理結果がatomicでなければならないか」に着目する
処理結果がatomicである必要があるということは「一連の処理をフェーズ分割することも、実行単位を小分けすることもできず、一つのトランザクションとして実行する必要がある」ということです。こうした処理の途中でエラーが発生した場合は、最初から実行し直す必要があります。
実行結果がatomicでなければならない場合は、処理が失敗した場合に正常にrollbackされるように実装します。実装の際は、処理失敗のやり直し時に同様のエラーで再失敗してしまう可能性を下げるため、できるだけログに詳しい情報を出力し、1回のやり直しで成功させられるように情報を残しておくことも重要です。
再実行が完全なやり直ししかないような「重い」バッチを実装する場合のコツとして、元データのエラーチェックをメイン処理の中で逐次に行うのではなく、処理の前半にまとめて行っておくことで早めにエラーを発生させる、という方法があります。
1時間かかるバッチ処理の最初の10分でエラーが発生するのと最後の10分でエラーが発生するのでは、リトライのためにかけられる時間が大きく変わってきます(早く失敗するということはその分無駄になる時間が短いということです)。
データフォーマットチェックやNULLチェックなどの単純にチェックできるようなエラー処理はバッチ処理の前半に持ってきておくことで、バッチ実行失敗時のリスクを小さくすることが可能です。
他テーブルに跨がったデータ整合性チェックなどの複雑な条件は前処理でチェックが難しいですが、CSVやJSON/XMLなどに対する項目数や文字数チェック、フォーマット違反チェックなどは単純なコードで実装できる割に効果の高いものなので、実行時間の長いバッチを実装する場合には検討するとよいでしょう
3. データを小刻みに確定させる
処理したいデータ全体としてatomicにする必要がない場合には、atomicにしないといけない処理単位を小分けにして細かい単位で完了させていくという方法が有効です。
たとえば、ある締め処理が、特定の1ユーザーの異常データが原因で失敗した場合を考えてみましょう。全ユーザーをまとめたトランザクションとして設計すると、一人分でも異常なデータがあれば処理にかけた時間は全て無駄になりますが、1ユーザーごとのトランザクションで処理するようにしておけば、異常データのあるユーザー以外は正常に確定させることができます。
再実行の場合も、既に処理の終わったユーザーはスキップし、未処理のユーザーだけ処理するようなロジックを実装しておけば、全件処理し直す場合に比べて再実行が圧倒的に早く終わります。
バッチ処理の分割
バッチ処理をフェーズに分けてフェーズ単位で可能な形で適切に分割することで、個別の処理を確実に実行しやすくなります。
例えばリモートから大規模なCSVデータを取ってきて内容を解析しつつDBに取り込んでいくような処理の場合、
- データ取得フェーズ(SCPやS3 Getなど)
- 取得したデータのvalidationフェーズ(カラム数チェックやフィールド長チェック)
- DB取り込みフェーズ
の3段階に分けることでやり直しがしやすくなります。
また、失敗した場合もバッチが分かれていることで「どのフェーズで失敗したか」がすぐに分かるというメリットがあるため、運用上も利点があります。
1. 個別のバッチが行う処理を明確化する
※ここで扱う用語はシステムや文化によって微妙に異なる名前になることがあります(タスク、ジョブネットなど)。適宜読み替えて下さい。
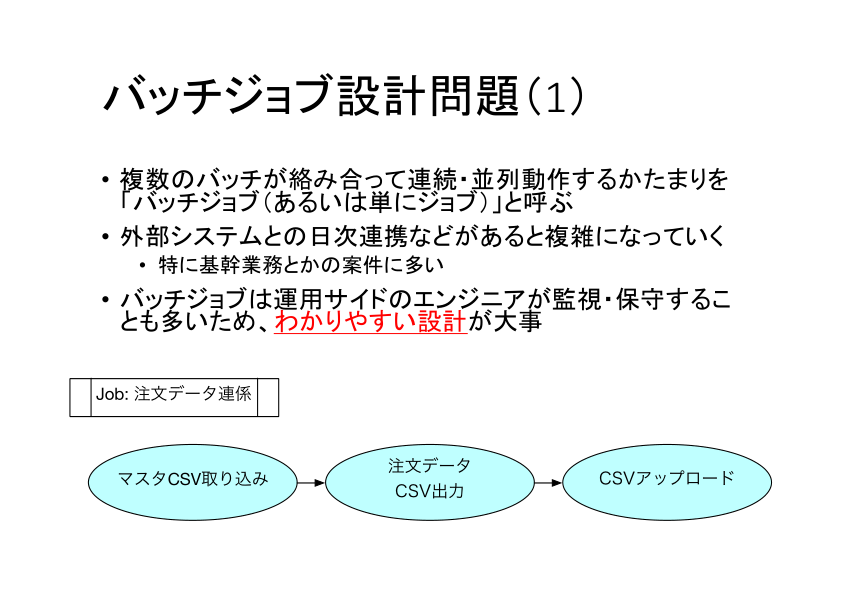
ジョブ(あるいはバッチジョブ)とは、連続または並列で動作するいくつかのバッチのまとまりを指す単位です。上の図で言うと、青が個別のバッチであり、それを取りまとめる「注文データ連携」がジョブになります。
バッチジョブは開発者とは別の運用側のエンジニアが監視・保守することも多いので、設計時に適度な粒度のバッチに分割するなどして、個別のバッチが何を行うのかを明快にしておきます。
運用を見越して考える場合は、失敗した場合や想定より長く時間がかかってしまっている場合に「このバッチが失敗・未完了ならシステムにはこういう問題が発生するはず」というのが明確であることが望ましいです。
2. バッチの分割を検討する

第2のポイントは、時間のかかる処理をなるべく複数のバッチに分割することです。「データ取り込みのバッチ」「バリデーションのバッチ」「データ処理のバッチ」「データ保存のバッチ」というように、処理の内容に応じた分割はもちろん、アトミックでない処理ならたとえば1000件ずつに水平分割することも検討します。
繰り返しますが「バリデーション(単純データチェック)のバッチ」を分けておくのは非常に有用なので、優先的に分割しましょう。バリデーションのバッチは他でも使えることが多いので、独立したバッチにしておくと後々助かります。
3. バッチは再実行可能にしておく
最も重要なのは第3のポイントで、バッチをできる限り個別に再実行可能な設計にすることです。個別に再実行可能な設計になっていないと、原状復帰したうえでジョブを最初からやり直さなければならなくなり、大きな時間ロスになります。
目安として、たとえば1時間かかる処理を「20分ごとの再実行可能な処理」3つに分割しておくと、やり直しも20分単位で済みます。分割されていないと、最後の1分で失敗したらまた1時間かけてやり直さなければならなくなります。
あまりに細かい単位(秒単位で終わる処理など)に分割しても煩雑になりすぎるので、作業のしやすい単位での分割を心がけましょう。
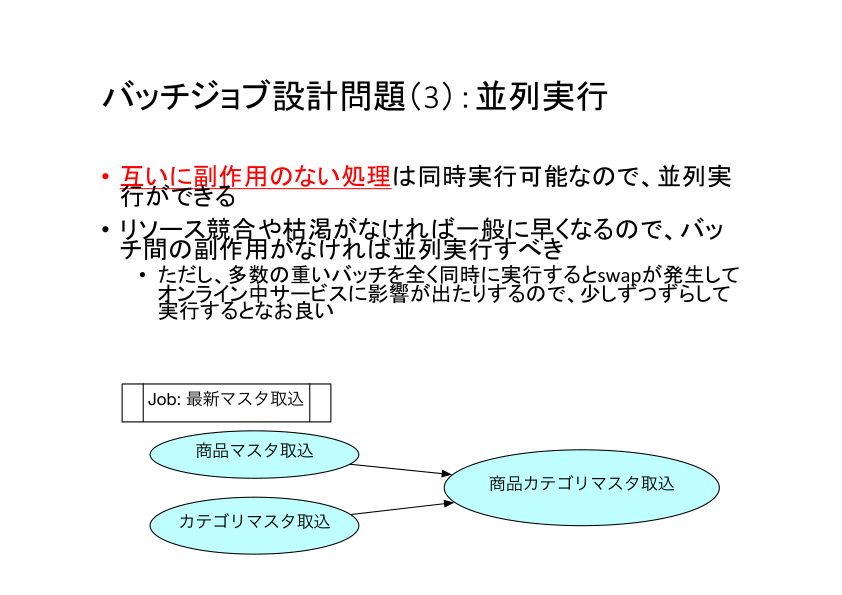
また、互いに副作用を及ぼさない処理は同時並行での実行が可能です。たとえば「独立したマスタデータの取り込み」などは互いに影響を及ぼさないため同時に実行することで並列度を上げることが可能です。
一方で、並列度を上げる際にはリソース競合や枯渇が生じないよう注意が必要です。並列化については次で少し詳しく説明します。
並列化(同時実行)の注意点

処理の並列化は可能であれば実施することが望ましいのですが、安易に並列化すると逆効果になることもあります。
複雑なトランザクションはロジックそのものがテーブルロックなどに依存しているケースがあります。このような処理を並列化するとマルチスレッドで動作させてもリソース競合が発生し、実質シングルスレッドでしか処理できないので並列化の効果が薄くなってしまいます。
こうした場合は並列度を上げても処理の完了までの時間は短くならないので、高速化が必須ならボトルネック調査を行いCPUなりDBのスループットを上げるなどの対応が必要になるでしょう。
また、並列化を行うと何らかの理由で複数のバッチが同時に異常終了してしまった場合のリカバリは複雑になります(例:DBサーバーがメモリ不足で落ちてしまった、など)。
一般に処理は高速な程良いですが、メンテナンスや障害時のことを考えると要件に対して十分な速度が確保できている範囲では速度よりも設計のシンプルさを取るという選択肢もあるということは抑えておきたいです。
並列化の効きやすい処理
一般に並列化がうまく機能するケースを挙げてみましょう。

1. 巨大データのブロック処理
大量のデータをDBからフェッチして1000件ずつなどの「ブロック単位」に分け、分けられたブロックを並列化するという方法です。処理が「読み込み」や「計算」などのフェーズに分かれている場合は、うまく時間をずらして実行すると効率の向上が期待できます。
並列化及び1ブロック単位の実行件数は10であったり100であったりとさまざまですが、「このぐらいの個数に分ければよい」というような一般法則はありませんので、いい感じのポイントはベンチマークによって調べるのが良いでしょう。
なお、並列化の単位が細かすぎると(1件ずつなど)リソース競合の都合でかえって遅くなることもあるため、そういった意味でもベンチマークによる計測と並行して行うのが大事になります。
なお、実装する際には最低限「並列度」「1ブロックの件数」の二つは引数などで渡せるように作っておくと、ベンチマークが簡単にできるのでお勧めです。
2. 処理キューから処理を取り出して逐次処理する(Producer-Consumerパターン)
Sidekiqなどの処理キューに積まれたジョブの処理は、処理がジョブ単位にまとまっているので、ワーカーを増やすだけで並列化ができます。
代表的なユースケースは動画や画像の変換処理などで、1つ1つのジョブが他のジョブに影響を与えないジョブ同士の独立性がポイントになります。
ジョブを詰んで別のワーカーで処理するという非同期実行は昨今のリッチなフレームワークでは大抵備えているため(例:RailsのActiveJob)、基本はそうしたフレームワークの推奨利用方法に従って実装するのが良いでしょう。
- #1 処理時間とレスポンス時間
- #2 バッチ処理とオンライン処理
- #3 バッチ処理を設計するときの注意点(本記事)
- #4 オンライン処理とUXの工夫
- #5 Railsのジョブ管理システムと注意点
- #6 バッチ処理ですぐに使えるノウハウ、まとめ
データ量と処理時間の関係は一概に比例とは限らず、指数的に増加するケースもあれば、量が増えても誤差レベルに収束する場合もあります。
特に注意したいのは指数的に増加するケースです。開発時の数件~数十件程度のデータでは全く問題がなかったのが、本番稼働後に数千件程度データ投入した辺りで著しく性能低下するようなケースは設計の甘いケースで割と目にします。
パフォーマンスチューニングは開発段階ではYAGNI(You ain't gonna need it: 必要になるまでは手を付けるべきでない)と見なされやすい部分ではありますが、開発中でも当初想定データの10倍くらいまでは「ここのデータ量が増えたらこの処理ってまともに動くのだろうか?」程度の想像を働かせておかないと、リリース直後の障害に繋がってしまう可能性すらあるので注意です。
特に、RubyやJavaのようなオブジェクト指向言語の場合、大量のレコードを一括処理する際にオブジェクト生成が絡むとメモリ不足で一気にパフォーマンスが低下したり、最悪プロセスが落ちてしまったりするといった問題に繋がる可能性があります。