Railsスケーリング(5): 待ち行列理論でジョブキューのパフォーマンスを理解する
本記事は、「Railsをスケーリングする」シリーズのパート5です。
🔗 キューイングシステム
Webアプリケーションのタスクには、即時に処理しなくてもよいものもあります。巨大な動画ファイルのアップロードや、キャンペーンメールの一括送信、複雑なレポートの生成のような時間のかかる操作はバックグラウンドで実行するのが普通です。SidekiqやSolid Queueのようなキューイングシステムが役に立ちます。
待ち行列理論(queueing theory)は、システムの平穏状態からピーク負荷時までのさまざまな状態におけるシステムの振る舞いを理解するのに有用です。
それでは待ち行列理論の基本を理解しましょう。
🔗 待ち行列理論の基本的な用語
- 1. 作業単位(Unit of Work)
- サービスを必要とする個別の項目、すなわちジョブ(job)を指します。
- 2. サーバー(Server)
- これは「パラレル処理能力の単位」です。待ち行列理論におけるサーバーは、必ずしも物理サーバーとは限らず、一度に1つの作業単位を処理できる能力を指します。
JRubyやTruffleRubyはパラレル実行能力を持つため、個別のスレッドを独立した「サーバー」とみなせます。
CRubyやMIRはGVLが存在するため、「サーバー」の概念が異なります(後述)。 - 3. 待ち行列の規律(Queue Discipline)
- これは、キュー内のどの作業単位を選択するかを決定するルールです。SidekiqやSolid Queueの場合はFCFS(First Come First Serve: 先着順に処理)が規律として採用されています。キューが複数ある場合、どのジョブを選択するかはキューの優先順位によります。
- 4. サービス時間(Service Time)
- 作業単位を処理するのにかかった実時間(ジョブを実行し終わるまでの時間)。
- 5. レイテンシ/待ち時間(Latency/Wait Time)
- ジョブが処理される前にキューで待たされる時間。
- 6. 合計時間(Total Time)
- サービス時間と待ち時間の合計。ジョブがエンキューされてから実行完了するまでの所要時間です。
🔗 リトルの法則
待ち行列理論におけるリトルの法則(Little's law)は、「あるシステム内におけるジョブの平均件数は、新しいジョブの平均到着率とシステム内におけるジョブの平均処理時間をかけたものに等しい」というものです。
L = λW
L= システムの平均ジョブ件数λ= 新しいジョブの平均到着率W= システム内におけるジョブの平均処理時間
たとえば、ジョブが平均で1分あたり10件到着し(λ)、個別のジョブが完了するまで30秒(W)要したとすると、以下のように求められます。
システムの平均ジョブ件数 = 10(ジョブ/分) * 0.5(分) = 5(ジョブ)
このLは提供トラフィック(offered traffic)とも呼ばれます。
原文追記: リトルの法則では、到着率は時間の経過とともに変わらないことが前提とされています。
🔗 利用率の管理
利用率は、処理能力(キャパシティ)がどの程度ビジー状態であるかを測定します。
数学的には、「処理可能なキャパシティ」に対する「利用中のキャパシティ」の比率で表されます。
利用率 = (システムの平均ジョブ件数 / 処理可能なジョブ件数) * 100
言い換えると以下のように求められます。
利用率 = (提供トラフィック / パラレリズム) * 100
たとえば、バックグラウンド処理の管理にSidekiqをシングルスレッドで使っている場合、このパラレリズムはSidekiqのプロセス数に等しくなります。
実際の事例を数字で見てみましょう。
- ジョブが毎分30件到着する
- ジョブ1件の処理に0.5分要する
- Sidekiqプロセス数は20
この場合の利用率は以下のようになります。
利用率 = (30(ジョブ/分) * 0.5(分)/20(プロセス)) * 100
= 75(%)
🔗 利用率が高いとパフォーマンス悪化につながる
システムの利用率を100%に維持していると仮定しましょう。つまり、平均して1分あたり30件のジョブを処理するということは、1分あたり30件のジョブを処理するとキャパシティがいっぱいになるということです。
そんな状態で、ある日のジョブが1分あたり45件に増加したとすると、利用率が100%だったため負荷の増加に対応できなくなり、レイテンシの増加につながります。
つまり、利用率が高いままになっていると、特定のジョブでレイテンシが増加してパフォーマンスが悪化する可能性があるということです。
🔗 レイテンシは急上昇する
数学的に考えれば、レイテンシが急増するのは利用率が100%に達したときだけのように思えますが、現実には利用率が70〜75%に達したあたりからレイテンシが急上昇することがわかっています。
利用率とパフォーマンスの関係をグラフに表すと、以下のような急カーブを描きます。
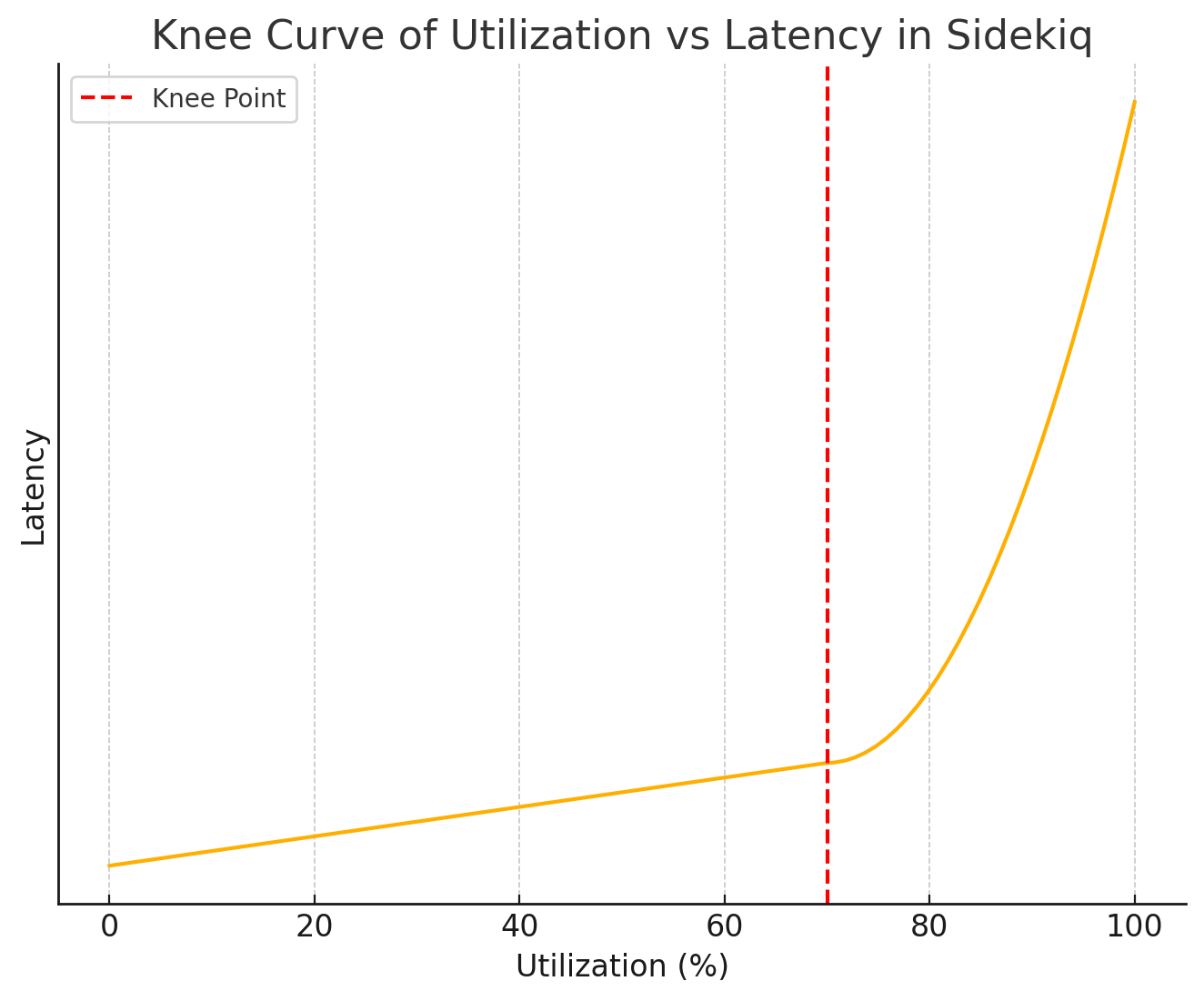
パフォーマンスのグラフが上向きに急上昇するポイントは「膝(knee)」と呼ばれます。この部分で待ち行列理論で予測される指数関数的効果が顕著に現れて、キューのレイテンシが急上昇します。
システムの利用率が恒常的に70〜75%を超えていると、ジョブの待ち時間がどんどん増えて、レイテンシが急上昇するリスクが著しく増加します。
そうなると、メール送信や、TwilioのSMSメッセージ発信などの処理が遅延して、顧客のエクスペリエンスが直接悪化する可能性もあります。
このレイテンシのトラッキングについては今後の記事で取り上げる予定です。メトリクスのトラッキング方法は、利用するキューイングバックエンド(SidekiqやSolid Queue)によって変わってきます。
🔗 コンカレンシーと、「理論上の」パラレリズムの違い
Sidekiqのパラレリズムにおけるメインの単位は、プロセスです。
しかし、コンカレンシー(1プロセスあたりのスレッド数)は、プロセスの実質的なスループットに大きく影響します。これは、ジョブのI/O待ちにどのぐらいかかるかを考えるときにGVLの影響も考慮しておく必要があるためです。
ジョブの実行時間で、Rubyコードの実行の占める時間よりも外部リソース待ち(データベースやAPIなど)の占める時間が増えてくるほど、同一プロセス内で最初のスレッドが待ち状態の間に別のスレッドがRubyコードをその分多く実行できるようになります。
本シリーズのパート2で以下のアムダールの法則を学びました。
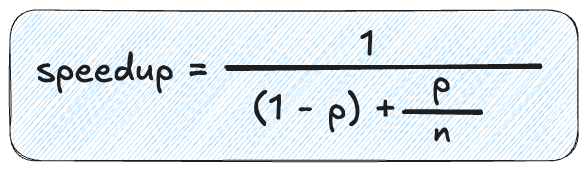
ただしpはパラレル化された部分(I/Oの割合)、nはスレッド数(コンカレンシー)を表します。
この文脈では、スピードアップは「理論上の」パラレリズムと等しくなります。
一方、待ち行列理論におけるパラレリズムは、同時処理可能な作業単位の個数を指します。
アムダールの法則を用いてスピードアップを算出する場合、本質的には「マルチスレッドのシステムがシングルスレッドのシステムより何倍高速になるか」を決定しようとしていることになります。
I/O処理がシステムの50%を占めていて、コンカレンシーが10の場合、スピードアップは以下のように求められます。
スピードアップ = 1 / ((1 - 0.5) + 0.5 / 10) = 1 / 0.55 = 1.82
≈ 2
つまり、スレッドを10個持つSidekiqプロセス1個は、シングルスレッドのSidekiqプロセス1個の倍の速さでジョブを処理できることになります。
ここまでの話をまとめてみましょう。
システムのI/Oが50%であると仮定します。システムは10スレッド(コンカレンシー)で単一のSidekiqプロセスを使っています。
スレッド数が10なので、システムは1スレッドのみのシステムと比較して2倍の速度向上を実現します。
しかし言い換えれば、10スレッドを実行しているからといって、パフォーマンスが10倍向上するわけではありません。この10スレッドによって得られるのは「理論上のパラレリズム」と呼ばれるものです。
以下のようにI/Oとコンカレンシーの割合を変えることで、同様に理論上のパラレリズムを得られます。
| I/Oが占める割合 | コンカレンシー(スレッド数) | 理論上のパラレリズム |
|---|---|---|
| 5% | 1 | 1 |
| 25% | 5 | 1.25 |
| 50% | 10 | 2 |
| 75% | 16 | 3 |
| 90% | 32 | 8 |
| 95% | 64 | 16 |
もう一度繰り返しますが、最後の例で言いたいのは、システムのI/Oが95%の場合は、プロセスあたりのスレッド数を64個にすることで、同じシステムのシングルスレッド版より16倍パフォーマンスが改善されるということです。
グラフでは以下のようになります。
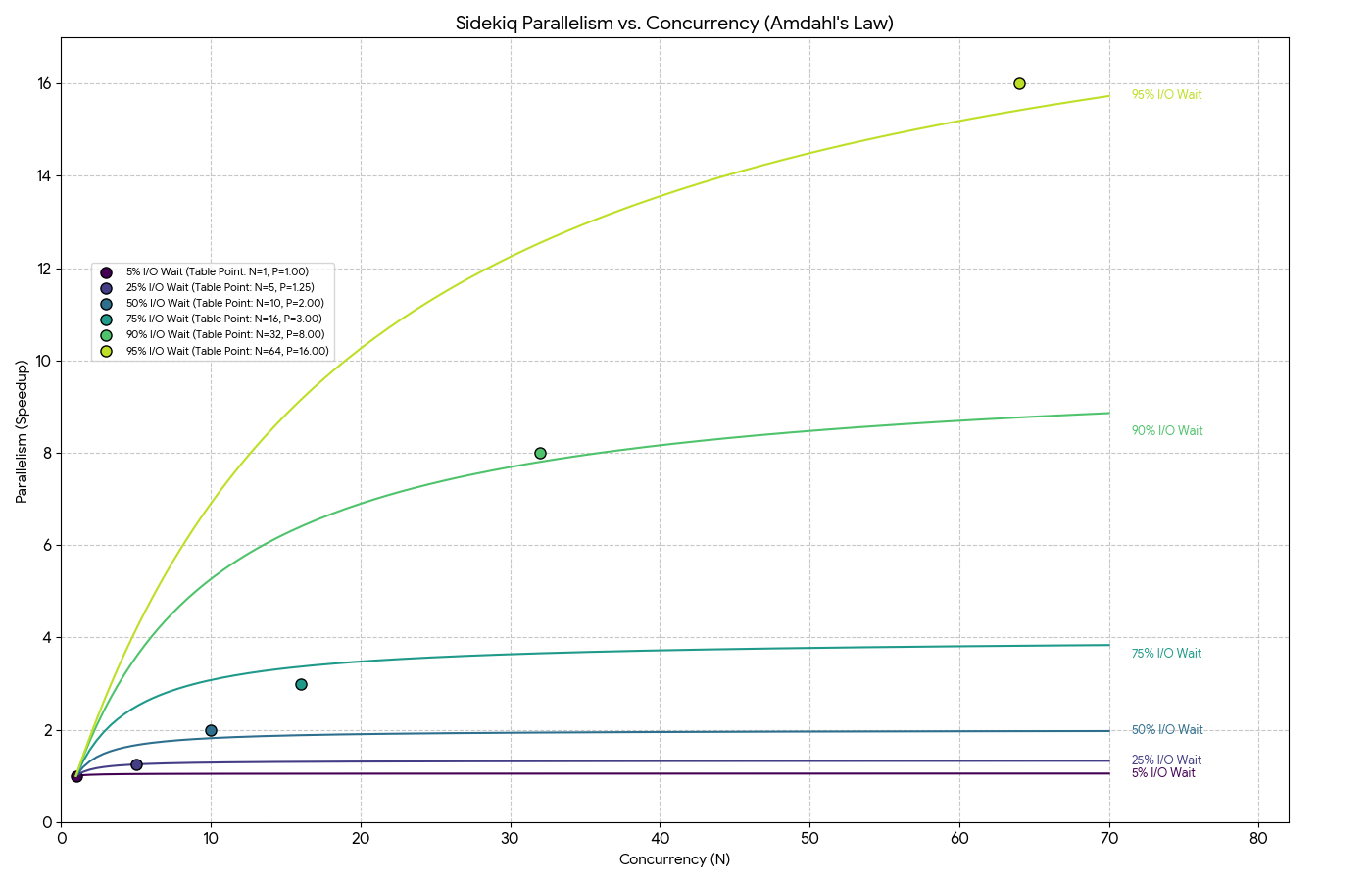
グラフに示されているように、16スレッドのSidekiqプロセスでI/Oバウンドのジョブを処理する割合が75%の場合、理論上のパラレリズムは3近くに達します。つまり、シングルスレッドシステムに比べてパフォーマンスが3倍近く向上します。
🔗 必要なプロセス数を算出する
本記事冒頭で「リトルの法則」について説明しました。Lは「提供トラフィック」とも呼ばれ、「システム内のジョブの平均件数」を表しています。
この「提供トラフィック」が5の場合、同時に処理する必要のある作業単位が平均5件到着することを意味します。
利用率が75%を超えるとレイテンシが急増するリスクが生じる可能性があることを学びました。
レイテンシを低くしなければならないキュー(urgentなど)では、利用率を下げる必要があります。安全のために、利用率は50%程度に抑えておきたいと思います。
利用率の目標と「提供トラフィック」がわかったので、これで「パラレリズム」を求められるようになりました。
利用率 = 提供トラフィック / パラレリズム
=> 0.50 = 5 / パラレリズム
=> パラレリズム = 5 / 0.50 = 10
すなわち、利用率を最大50%に留めるには、理論上のパラレリズムを10にする必要があります。
このキュー内にあるジョブの平均I/Oは50%だと仮定すると、上述のグラフから、コンカレンシーが10の場合はパラレリズムが2になることがわかります。
しかしコンカレンシーを増やしても、パラレリズムが増加するわけではありません。つまり、パラレリズムを10にしたいとすると、コンカレンシーを50に設定するだけでは不足なのです。仮にコンカレンシーを50にしたとしてもパラレリズムは2どまりです。
つまり、パラレリズムを増やすにはプロセスを追加する以外に方法はないということなのです。1プロセスでコンカレンシー10を得られるので、パラレリズム10を得るにはプロセスを5つ追加する必要があります。
Sidekiqで必要な総プロセス数 = 10 / 2 = 5

なお、本記事ではSidekiqの無料版で説明しています。無料版では、Herokuのdynoごとに利用可能なのは1プロセスのみです。Sidekiq Proをご利用の場合は、Sidekiq Swarmでマルチプロセスを実行可能になります。
urgentキューには5個のdynoをプロビジョニングできますが、ジョブの急増に対応するには、Judoscaleなどのキュー時間ベースのオートスケーラーを常に有効にしておく必要があります。
🔗 改善が飽和する原因
待ち行列理論では、通常は利用率が70~75%程度になると飽和点に到達すると説明しました。スレッドを追加するとパフォーマンス向上を期待できるという観点では、このような見解になります。
ただし、飽和はシステムの他の部分で生じている可能性もあります。
🔗 1: CPU
Sidekiqプロセスを実行するサーバーのCPUとメモリは有限です。CPU使用率はSidekiqでトラッキング可能な指標の1つですが、スケーリングの決定において注目すべき指標は他にもあるのが一般的です。
CPU使用率だけをチェックすると解釈を誤る可能性があります。ジョブのほとんどの時間がI/O(API呼び出しやデータベースクエリなど)に費やされている場合、Sidekiqシステムがフル稼働していてもCPU使用率は非常に低くなります。
🔗 2: メモリ
メモリ使用率は、CPU使用率とまったく異なる形でパフォーマンスに影響を与えます。メモリ使用率が0%〜100%のうちは、レイテンシやスループットにほとんど変化がありませんが、100%を超えるとパフォーマンスは著しく低下し始めます。システムでスワップメモリが使われるようになると非常に低速になり、それによってジョブの処理時間が長くなる可能性があります。
🔗 3: Redis
飽和発生の可能性があるもう1つの場所は、データストアです(Sidekiqを使っている場合はRedisがデータストアになります)。その場合は、Sidekiqで使うRedisの別インスタンスをプロビジョニングし、さらにエビクションポリシーをnoevictionに設定する必要があります。こうすることで、Redisはメモリ上限に達したときに新しいデータを拒否して失敗を明示的に報告し、重要なジョブが無言で捨てられないようにできます。
概要
元サイトの許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。
queueing theoryは「待ち行列理論」、queueing systemはキューイングシステムとしました。
参考: 待ち行列理論 - Wikipedia