こんにちは。
今回は内容が盛り沢山なので、前編と後編に分割します。
今回の解説範囲
平成30年度 春期 データベーススペシャリスト試験 午後Ⅰ 問3
⚓ 設問1 (3)
作業W4(追加制約設計)に関する表4の索引について、①、②に答えよ。
実際に問題を解く前に、設問に関する情報を問題文中から探し整理していきましょう。
図1 主なテーブル構造(抜粋)
- 鍵(
施設ID,鍵番号,券番号,使用中フラグ)- 店舗利用(
利用時刻,施設ID,店舗ID,鍵番号,商品ID,利用額,ポイント数,未精算フラグ)- 精算明細(
利用年月日,利用時刻,施設ID,券番号,店舗ID,商品ID,利用額,ポイント数)
* 実線の下線は主キーを表しています。
表2 物理DB設計及び実装の作業工程表(抜粋)
| 作業順 | 作業ID | 作業名 | 作業内容 |
|---|---|---|---|
| 4 | W4 | 追加索引設計 | DMLのアクセスパスを想定し、性能向上のために追加索引を設計する |
⚓ 表3 利用額の精算時に実行されるDMLの例
| DML | DMLの構文 |
|---|---|
| DML1 | SELECT 券番号FROM 鍵WHERE 施設ID = :施設ID AND 鍵番号 = :鍵番号 |
| DML2 | INSERT INTO 精算明細()SELECT :利用年月日, 利用時刻, 施設ID, :券番号, 店舗ID, 利用額, ポイント数FROM 店舗利用WHERE 施設ID = :施設ID AND 鍵番号 = :鍵番号 AND 未精算フラグ = 'Y' |
| DML3 | SELECT FROM 精算明細WHERE 利用年月日 = :利用年月日 AND 施設ID = :施設ID AND 券番号 = :券番号 |
注記1 網掛け部分は表示していない。
注記2 ホスト変数の利用年月日には, 当日の現在日付が設定される。
各DMLを日本語に直すと以下の通りです。
- DML1: それぞれのホスト変数と一致する
施設IDと鍵番号を持つ行を鍵テーブルから選択し、鍵番号を射影する。 - DML2: それぞれのホスト変数と一致する
施設IDと鍵番号を持ちなおかつ未精算フラグが'Y'の行を店舗利用テーブルから選択し、利用年月日(ホスト変数)、利用時刻、施設ID、券番号(ホスト変数)、店舗ID、利用額、ポイント数列を射影して精算明細テーブルに挿入する。 - DML3: それぞれのホスト変数と一致する
利用年月日、施設ID、券番号を持つ行を精算明細テーブルから選択する。
* DDL、DML、DCLの定義や区別をお忘れの方は逆引きSQL構文集でおさらいしておきましょう。
⚓ 表4 DML2及びDML3のために追加した索引
| 索引 | 設計対象のDML | テーブル名 | 索引のキーの構成 |
|---|---|---|---|
| 索引1 | DML2 | 店舗利用 | 施設ID, 鍵番号, 未精算フラグ |
| 索引2 | DML3 | 精算明細 | 利用年月日, 施設ID, 鍵番号 |
設問1 (3) ① 解説
①: 索引1は, ユニーク制約又は非ユニーク制約のどちらに該当するか答えよ。
まずは、「ユニーク制約」と「非ユニーク制約」とは何かが分からなければ問題に答えられないので、定義を確認しておきましょう。
IBM Knowledge Centerによると、それぞれ以下のように定義されています。
ユニーク索引は、表内のデータの 2 つの行が同一のキー値を持たないようにすることによりデータ整合性の維持に貢献する索引です。
データが入っている既存の表にユニーク索引を作成する場合、索引キーを構成する列または式の値について固有性がチェックされます。キー値が重複する行を含む表では、索引の作成処理が失敗します。表にユニーク索引を定義した場合、索引内でキーが追加または変更されるときには必ず、固有性が強制されます。強制される操作の例をいくつか挙げると、挿入、更新、ロード、インポート、整合性の設定などがあります。
(一部省略)
非ユニーク索引は、その索引が関連付けられる表に対して制約を適用するために使用されることはありません。その代わり、非ユニーク索引は、頻繁に使用されるデータ値のソート順序を維持することにより照会のパフォーマンスを改善するためだけに使用されます。
まとめると以下の通りになります。
| 制約名 | 一意性 | NULL値の許容 | 特徴 |
|---|---|---|---|
| ユニーク制約 | 保証する | ユニーク制約が一つの列 => NULL値は一つのみ許容する
ユニーク制約が複数列 => 値とNULL値の組み合わせで1つのみ許容する |
索引の作成時に重複する行は存在出来ない |
| 非ユニーク制約 | 保証しない | 許容する | 頻繁に使用されるデータ値のソート順序を維持し、照会のパフォーマンスを改善するためだけに使用 |
次に、表1でそれぞれのキーの意味・制約を確認しましょう。
| 列名 | 意味・制約 |
|---|---|
| 鍵番号 | 施設内のロッカーを識別する番号。客の精算後、鍵は再利用される。 |
| 未精算フラグ | 利用額が未精算の場合:'Y' 精算済みの場合:'N' |
ここで、具体的なシナリオを考えてみましょう。
ある日、Aさん、BさんCさんが施設を利用しました。
Aさん、Bさんは既に精算済みで、三人はたまたま入れ替わりで同じロッカーの鍵番号を渡されました。
施設内の店舗で商品を購入するごとに、店舗利用テーブルには例えば以下のような行が追加されます。
利用時刻 |
施設ID |
店舗ID |
鍵番号 |
商品ID |
利用額 |
ポイント数 |
未精算フラグ |
|---|---|---|---|---|---|---|---|
| 11:00:00 | 001 | 010 | 030 | 101 | 3500 | 100 | 'N' |
| 12:00:00 | 001 | 011 | 030 | 202 | 2000 | 70 | 'N' |
| 13:00:00 | 001 | 012 | 030 | 303 | 2500 | 85 | 'Y' |
* 一行目をAさん、二行目をBさん、三行目をCさんとします。
キーの意味・制約を見ると、「客の精算後、鍵は再利用される。」とあり、ある客の未精算フラグが'N'であれば、他の客が同じ鍵番号を利用出来ますので、キー値が重複しても問題ありません。
よって、上記のように違う客が施設ID、鍵番号、未精算フラグにおいて同一のキー値を持つことが出来ますので、ユニーク索引を設定することは出来ません。
よって、非ユニーク索引が正解となります。
ちなみに、非ユニーク索引設定のために実行されるDDLは以下の通りです。
CREATE INDEX [索引名]
ON 店舗利用 (施設ID, 鍵番号, 未精算フラグ)
設問1 (3) ② 解説
②: 索引2は高クラスタな索引である。その理由を35字以内で答えよ。
まずは、問題文にある高クラスタ・低クラスタの説明を確認しましょう。
- 高クラスタな索引:キー値の順番と, キー値が指す行の物理的な並び順が一致しているか, 完全に一致していなくても, 隣接するキーが指す行が同じページに格納されている割合が高い。
- 低クラスタな索引;キー値の順番と, キー値が指す行の物理的な並び順が一致している割合が低く, 行へのアクセスがランダムになる。
ここで、ページという用語が登場しました。
日経 XTECHでは、図とともに以下のように解説されています。
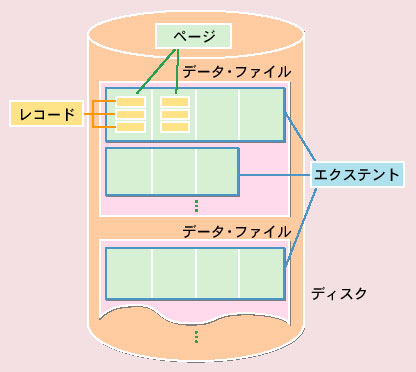
ページはRDBMSがディスク領域を管理する際に基本となる単位で...
(一部省略)
テーブルを構成するレコードや,インデックスのエントリを複数格納します。RDBMSはメモリーとディスクの間の入出力をページ単位で管理し,キャッシュ・バッファへの入出力もページごとに行います。
(一部省略)
ページ・サイズの決定は,RDBMSのパフォーマンスに影響を与えます。扱うデータやアクセスの特性に合わせて決める必要があります。例えば,1回の入出力で扱う平均的なデータ量が少ない場合には,ページ・サイズが小さいほうが有利です。レコードを一つだけ読み込めばいいような場合でも,ページ全体を読み込むことになり無駄が多くなるからです。一方,1回の入出力で扱うデータ量が多い場合は,ページ・サイズを大きくしたほうが良いでしょう。ページ・サイズが小さいとディスクとの入出力の回数が増えて,効率が悪くなります。
基礎から理解するデータベースのしくみ(6)_日経 XTECHより引用
上の図を見ながらイメージしてみて下さい。
探索対象の複数の行が規則正しく同じページに格納されていたら、ページへのアクセスはごく少なくて済みます。
この状態を問題文で「高クラスタ」と定義されています。
反対に、お目当の行がバラバラのページに不規則に格納されていたら、ページにランダムにアクセスしなければなりません。
この状態を「低クラスタ」と定義されています。
この設問では、何故索引2は高クラスタなのかを聞いています。
今一度、表3 利用額の精算時に実行されるDMLの例を見て下さい。
DML3でSELECT文を使って探索される精算明細テーブルの行は、DML2に挿入されるのが分かります。
この挿入はどのタイミングで行われるのでしょうか?
問題文「施設運営及び会員カードの概要 1.施設運営 (4)」に大きなヒントが書かれています。
レジに記録されたデータは、客が精算するまでにシステムのデータベースに送られる。
ここでのレジは店舗利用テーブル、システムのデータベースは精算明細テーブルを指しています。
券番号111を持つ客が、施設内の店舗内で色々な商品をバラバラのタイミングで購入したとしましょう。
店舗利用テーブルには行がバラバラに挿入されているはずですが、
券番号111に紐づいたデータは、精算時までに「まとめて」精算明細テーブルに追加されます。
よって、以下のように行が追加されます。
利用年月日 |
利用時刻 |
施設ID |
券番号 |
店舗ID |
商品ID |
利用額 |
ポイント数 |
|---|---|---|---|---|---|---|---|
| 20190131 | 11:00:00 | 001 | 111 | 011 | 3445 | 1000 | 100 |
| 20190131 | 14:00:00 | 001 | 111 | 023 | 9384 | 400 | 40 |
| 20190131 | 16:00:00 | 001 | 111 | 034 | 1934 | 300 | 50 |
| 20190131 | 17:00:00 | 001 | 111 | 045 | 3415 | 200 | 20 |
| 20190131 | 19:00:00 | 001 | 111 | 056 | 2155 | 100 | 10 |
| 20190131 | 21:00:00 | 001 | 111 | 067 | 4868 | 1000 | 100 |
このように追加されれば、同じページにレコードがまとまって存在することになり、「高クラスタ」な状態になります。
よって、「同じ券番号の行が精算時にまとめて追加されるから」が解答になります。
さて、記事が長くなってきましたので、設問1 (4)は後編に続きます。
今回の設問の解答
- 設問1 (3)
- ①
非ユニークキー - ②
同じ券番号の行が精算時にまとめて追加されるから
- ①
参考ページ
- 平成30年度 春期 データベーススペシャリスト試験 - IPA情報処理推進機構 - 最終アクセス日: 2019年02月05日
- ユニーク制約と非ユニーク制約 - IBM Knowledge Center - 最終アクセス日: 2019年01月28日
- 逆引きSQL構文集 - 最終アクセス日: 2019年01月29日
- 基礎から理解するデータベースのしくみ(6) - 日経 XTECH - 最終アクセス日: 2019年01月31日
次回解説予定範囲
平成30年度 春期 データベーススペシャリスト試験 午後Ⅰ 問3 設問1 (4)