こんにちは、hachi8833です。久しぶりに正規表現についての記事を書いてみました。
一応Ruby(Onigmo)を対象にしましたが、なるべく他の正規表現ライブラリでも通用する一般的な記述を心がけました。エッジケースを扱っているためシンタックスハイライトがついていけてない部分がありますのでご了承ください。
⚓ 文字クラス[ ]内のエスケープ
正規表現でのエスケープ、特に記号のエスケープは何かと面倒になりがちです。記号が出てくるたびに片っ端からバックスラッシュ\でエスケープしてばかりだと疲れてしまいます。
しかしつい忘れがちですが、正規表現の中でも文字クラス[ ]の中だけは別世界になっていて、文字クラスの外よりもエスケープが少なくてすみます。
あくまで原則としてですが、文字クラス[ ]の中に限り、以下の4つの記号だけがメタキャラクタ(=機能を持つ記号)として扱われます。
\- バックスラッシュ
(backslash): -- ハイフンマイナス
(hyphen-minus) ^- サーカムフレックス(俗に山形記号、キャレット)
(circumflex, hat sign、caret) ]- 閉じ角かっこ
(right square bracket)
ということは、それ以外の記号はエスケープなしで楽々と文字クラス[ ]内に置けることになります。本当に?本当に?
⚓ 文字クラス内メタキャラクタにも種類がある
ただし、上の中でバックスラッシュ\と他の3つのメタキャラクタは挙動が異なります。
バックスラッシュ\だけは絶対的なメタキャラクタであり、自分自身を含む直後の文字は何でもエスケープします。
逆に、ハイフンマイナス: -、山形記号: ^、閉じ角かっこ: ]の3つは、文字クラス[ ]内では相対的なメタキャラクタです。
具体的には、文字クラス[ ]の中に置く位置によって挙動が異なります。
⚓ 文字クラス[ ]内の山形記号^
山形記号^は、文字クラス[ ]内の冒頭に置くかどうかで挙動が変わります。
具体的には、文字クラス[ ]内の冒頭が山形記号^だと、文字クラスの否定という特殊な意味を表します(Rubularの実行例)。
[^0-9a-zA-Z]
上のようにすると、「英数字以外のあらゆる文字」を表します。これはよく使われるのでご存じの方も多いと思います。
実は、^は文字クラスの先頭以外の場所に置くのであればエスケープ不要です(Rubularの実行例)。
[0-9a-z^A-Z]
正確に言うと、先頭以外の場所であればエスケープしてもしなくて同じです。
⚓ 文字クラス[ ]内のハイフンマイナス -
文字クラス[ ]内のハイフンマイナス-は、範囲を表すメタキャラクタで、文字クラス[ ]の「冒頭または末尾」に置くかどうかで挙動が変わります。
[a-zA-Z]
上のように[a-zA-Z]とすると、小文字のaからzと、大文字のAからZの文字を表します。これもよく使われるのでご存じの方が多いと思います。
文字クラス[ ]内でハイフンマイナス自体を表すには、\^のようにバックスラッシュでエスケープする方法のほかに、以下のように文字クラスの冒頭または末尾に置くことでもできます(Rubularの実行例)。
[a-zA-Z\-]
[-a-zA-Z]
上の文字クラスは、どちらも「単なるハイフンマイナス」「小文字のaからz」「大文字のAからZの文字」を表します。言い換えると、ハイフンマイナス-を文字クラス[ ]の「冒頭または末尾」に置くと、範囲を表さなくなります。
ここでも文字クラスの冒頭が特別扱いされています。
⚓ 文字クラス[ ]内の閉じ角かっこ ]
次がやや気色悪いです。
文字クラス[ ]内の冒頭が閉じ角かっこ ]だと、エスケープなしで通常の文字として扱われます。つまり、]は文字クラスの冒頭においた場合に限り機能しなくなります。
[a-zA-Z&*()\]]
[]a-zA-Z&*()]
たとえば上はいずれも、]a-zA-Z&*()のいずれかにマッチします。
とはいうものの、[]なんちゃら]などと書くと、間違って2回閉じてしまったように見えてしまうので、いくらバックスラッシュでエスケープしなくてよくなるからといっても使いたくないですね(少なくとも私は)。
普通に[a-zA-Z&*()\]]と]を\でエスケープする方がなんぼかましだと思います。
さらに、JavaScriptでは[]を空の文字クラスと認識する(regex101.comの実行例)など、実装によって変わる可能性が大なので、この挙動をあてにするとハマると思います。
⚓ 文字クラス[ ]内で「現実に」エスケープが必要なその他の文字
いよいよ本題です。
さきの原則どおりであれば、位置を意識せずに文字クラス内に記号を書くときは^-]\の4つの文字だけをエスケープすればよいことになります。
!"#$%&'()*,-./:;<>?@[\]^_`{|}~
上はASCIIの記号たちです(UTF-8でも共通です)。これを文字クラスの中に書いてエスケープするとしましょう。例の4つのメタキャラクタ「^-]\」をエスケープすると以下のようになります。
[!"#$%&'()*,\-./:;<>?@[\\\]\^_`{|}~]

しかし実際にやってみると怒られます(Rubularの実行例)。

うすうす見当の付いた方もいらっしゃると思いますが、現実には4つのメタキャラクタの他に、少なくとも以下のエスケープも必要になることがあります。実装によってはこの他にもエスケープが必要になる記号があるかもしれません。
- 正規表現リテラルの開始記号と終了記号
- この記号は言語やライブラリによって異なる可能性があります。正規表現リテラルにスラッシュ
/を使う言語が多いようですが、少なくともRubyでは開始/終了記号を他の記号に変えることもできます。 - 開始かっこ
[ - これは実装に依存する可能性があります。少なくともRubyのOnigmoでは文字クラスの中で開始かっこ
[もエスケープが必要です。
というわけで、/と[もエスケープしてみました(Rubularの実行例)。
[!"#$%&'()*,\-.\/:;<>?@\[\\\]\^_`{|}~]
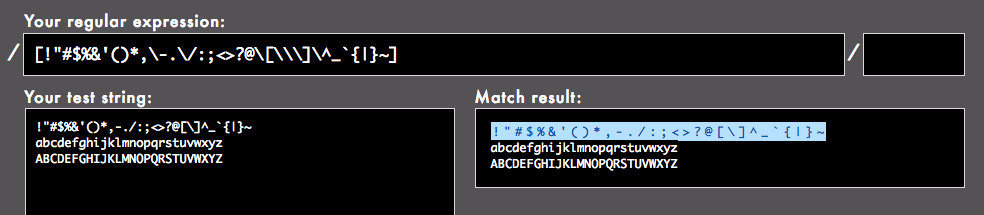
はい、今度はきれいにすべての記号にマッチしました。コロンもセミコロンもドル記号も引用符もパーセントもアンパサンドもハットもエスケープしてません。
まとめ
まとめると、少なくともRubyの正規表現の文字クラス内であれば、メタキャラクタである/と^と-と]、そのほかに/と[だけをエスケープすればよいことになります。さらに、^は先頭に置かないように注意すればエスケープ不要です。
それ以外の記号はエスケープなんかしなくたってよいのです(エスケープしても動きますが)。
ここまでわかれば、文字クラスの中をエスケープだらけにせずに安心して記号を書けるようになります。
以下の文字クラスではエスケープをひとつも使っていませんが、ちゃんと機能します(Rubularの実行例)。
[#$@%&*._^(){}]
これでエスケープの強迫観念がだいぶ軽くなった気がします。
おまけ
ついでながら、文字クラス[ ]の中には順序の概念がありません(例の4つのメタキャラクタの振る舞いはもちろん除きます)。
したがって、[bar]でも[abr]でも同じです。
間違えられやすいのですが、[^bar]は「"bar"でない文字」ではなく、「"b"でも"a"でも"r"でもない1文字」です。
おまけ 2
参考までに、RubyやPerlや.NET Frameworkなどにバンドルされているリッチな正規表現ライブラリで、かつ対象がASCII限定であれば、以下のようにUnicodeのカテゴリを指定してASCIIの全記号にマッチさせることもできます(Rubularの実行例)。JavaScriptやsed/awkなどでは残念ながら標準ではサポートされていません。
[\p{P}\p{S}]
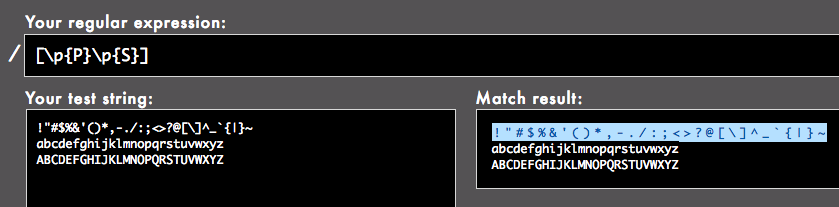
ただしこれは全角記号や句読点や絵文字を含むありとあらゆるUnicode内の記号にマッチする、やばいぐらい大ざっぱな正規表現です。対象がソースコードのようなものならともかく、一般的な文書だといらん記号にまでがんがんマッチするので大変なことになるかもしれません。
\p{P}はあらゆる約物(punctuation)、\p{S}はあらゆるシンボル(symbol)を表します。詳しくはUnicode Character Categoriesをご覧ください。
更新履歴