- Ruby / Rails関連
週刊Railsウォッチ(20200203前編)Railsの各種高速化コミット、OpenAPIの使い所、パンくずリストgem loaf、Railsビュー最適化ほか
こんにちは、hachi8833です。先週はコロナウイルスの件で福岡でのリモート公開つっつき会が延期になりましたので、規模を縮小して公開でないリモートつっつき会をWingdoorの皆さまと開催いたしました🙇。
- 各記事冒頭には⚓でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
- 「つっつきボイス」はRailsウォッチ公開前ドラフトを(鍋のように)社内有志でつっついたときの会話の再構成です👄
- 毎月第一木曜日に「公開つっつき会」を開催しています: お気軽にご応募ください
⚓お知らせ: 週刊Railsウォッチ「第19回公開つっつき会」(無料)

いよいよ第19回を迎えた公開つっつき会は、今週2月6日(木)19:30〜よりBPS株式会社Pubスペースにて開催いたします。
週刊Railsウォッチの記事やここだけの話にいち早く触れられるチャンス!発言・質問も自由です。皆さまのお気軽なご参加をお待ちしております。
⚓Rails: 先週の改修(Rails公式ニュースより)
公式の更新情報は出ていないので、直近のコミットリストから見繕いました。最適化・高速化のプルリクが目に付きました。
⚓高速化: hash_rowsのビルドにtransform_valuesを使うよう変更
# activerecord/lib/active_record/result.rb#L141
def hash_rows
@hash_rows ||=
begin
# We freeze the strings to prevent them getting duped when
# used as keys in ActiveRecord::Base's @attributes hash
columns = @columns.map(&:-@)
length = columns.length
+ template = nil
@rows.map { |row|
- # In the past we used Hash[columns.zip(row)]
- # though elegant, the verbose way is much more efficient
- # both time and memory wise cause it avoids a big array allocation
- # this method is called a lot and needs to be micro optimised
- hash = {}
-
- index = 0
- while index < length
- hash[columns[index]] = row[index]
- index += 1
+ if template
+ # We use transform_values to build subsequent rows from the
+ # hash of the first row. This is faster because we avoid any
+ # reallocs and in Ruby 2.7+ avoid hashing entirely.
+ index = -1
+ template.transform_values do
+ row[index += 1]
+ end
+ else
+ # In the past we used Hash[columns.zip(row)]
+ # though elegant, the verbose way is much more efficient
+ # both time and memory wise cause it avoids a big array allocation
+ # this method is called a lot and needs to be micro optimised
+ hash = {}
+
+ index = 0
+ while index < length
+ hash[columns[index]] = row[index]
+ index += 1
+ end
+
+ # It's possible to select the same column twice, in which case
+ # we can't use a template
+ template = hash if hash.length == length
+
+ hash
end
-
- hash
}
end
end
つっつきボイス:「hash_rowsはprivateだそうです」「transform_valuesはRuby 2.4で追加されたらしい↓けど、Ruby 2.7でさらに速くなったみたい😋」「😋」
「字が細かくて今読めないんですが、これはどういうメソッドでしたっけ?」「transform_valuesはハッシュの値をeachとかで回すんじゃなくて一括で変更できるみたいなヤツだったと思います: まあ覚えてたら使うかなというメソッド☺️」「なるほど」「使いみちとしては、値に共通のプレフィックスやサフィックスや引用符を付けたいときとか、値をまとめてエスケープしたいときとかかな」
参考: サンプルコードでわかる!Ruby 2.4の新機能と変更点 - Qiita
「Railsでこのtransform_valuesを使って速くしたということですね😊」「templateという一時変数を使ってるあたりのコードがよくわからななかったけど、どうやら以下のコメントあたりかな↓: Active Recordで同じカラムを2回selectできて、その場合はテンプレートは使えない、とそのまんまだった😆」「ふむふむ」「普段はテンプレートを使うけど、Active Recordで直接selectしたりして同じカラムを複数含む場合は従来の処理に切り替えるということと理解しました☺️」「速くなってよかった❤️」
# activerecord/lib/active_record/result.rb#L172
+ # It's possible to select the same column twice, in which case
+ # we can't use a template
+ template = hash if hash.length == length
+
+ hash
end
このコミットの変更点は、
hash_rowsは最初のrowについては以前と同じにビルドし、以後のrowについては最初のrowをテンプレートとしてtransform_valuesでビルドするようになったこと。
これはRuby 2.4(transform_valuesの最初のバージョンはここで登場)以降わずかに速くなった。理由はハッシュがreallocationされなくなったことと、ハッシュのupdateロジックがおそらくaddよりも少しシンプルになったため。
Ruby 2.7以降はこれがさらに速くなった。理由はtransform_valuesがキーをハッシュ化せずに実行できるようになって値のリストだけをイテレートするようになったこと。
今回の場合rowは1つしかないので、インスタンス変数のセット/リードと条件が1つ余分に増えたのみ。
同PRより大意
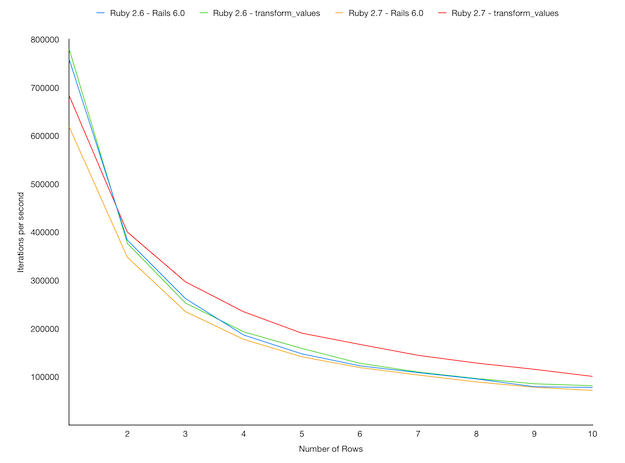
結果は以下のとおりでした。
同コミットより
⚓高速化: キャッシュのexpanded_key周り
# activesupport/lib/active_support/cache.rb#L678
def expanded_key(key)
return key.cache_key.to_s if key.respond_to?(:cache_key)
case key
when Array
if key.size > 1
- key = key.collect { |element| expanded_key(element) }
+ key.collect { |element| expanded_key(element) }
else
- key = expanded_key(key.first)
+ expanded_key(key.first)
end
when Hash
- key = key.sort_by { |k, _| k.to_s }.collect { |k, v| "#{k}=#{v}" }
- end
-
- key.to_param
+ key.collect { |k, v| "#{k}=#{v}" }.sort
+ else
+ key
+ end.to_param
end
つっつきボイス:「expanded_keyもprivateですね」「とりあえずexpanded_keyのソース見てみる↓」「どの辺がexpanded?😆」
# activesupport/lib/active_support/cache.rb#L678
def expanded_key(key)
return key.cache_key.to_s if key.respond_to?(:cache_key)
case key
when Array
if key.size > 1
key.collect { |element| expanded_key(element) }
else
expanded_key(key.first)
end
when Hash
key.collect { |k, v| "#{k}=#{v}" }.sort
else
key
end.to_param
end
キーをexpandしてstring値と一貫させる。オブジェクトが
cache_keyに応答する場合はcache_keyを呼び、そうでなければto_paramを呼び出す。キーがハッシュの場合はアルファベット順でキーがソートされる。
同APIより
「expanded_keyはキャッシュに保存するキーを取得するメソッドらしい🤔」「プルリクではkeyへの代入が削られてますね」「sort_byをsortに変えたり」「修正前だとkey = key.sort_by { |k, _| k.to_s }でハッシュが作られるけど、ハッシュを作らずにやる方法に変えたり」「挙動を変えないリファクタリングで高速化しているようですね☺️」「sortとcollectの順序も変わったみたい」「たしかにsortしてからcollectするよりcollectしてからsortする方が速いでしょうね😋」
このPRは
Cache::Store#expanded_keyの実装をクリーンアップする。いくつかの代入を削除して、ハッシュキーのcollectやsortの順序を変更した。
同PRより大意
「コスメティックなリファクタリングにも見えるけど、ベンチマークの結果を見るとArrayとHashがだいぶ速くなった💪」「Stringではほとんど変わらないけど☺️」
⚓リファクタリング: callbacks.rbのメモリ使用量を大幅に削減
# activesupport/lib/active_support/callbacks.rb#L294
def initialize(name, filter, kind, options, chain_config)
@chain_config = chain_config
@name = name
@kind = kind
@filter = filter
@key = compute_identifier filter
- @if = check_conditionals(Array(options[:if]))
- @unless = check_conditionals(Array(options[:unless]))
+ @if = check_conditionals(options[:if])
+ @unless = check_conditionals(options[:unless])
end
...
private
+ EMPTY_ARRAY = [].freeze
+ private_constant :EMPTY_ARRAY
+
def check_conditionals(conditionals)
+ return EMPTY_ARRAY if conditionals.blank?
+
+ conditionals = Array(conditionals)
if conditionals.any? { |c| c.is_a?(String) }
raise ArgumentError, <<-MSG.squish
Passing string to be evaluated in :if and :unless conditional
options is not supported. Pass a symbol for an instance method,
or a lambda, proc or block, instead.
MSG
end
- conditionals
+ conditionals.freeze
end
つっつきボイス:「修正前はメモリ使用量7MBぐらいだったのが修正後はKB単位にまで減ってますね」「@ifと@unlessで余計なarrayを生成しないようにしたということか😋」「おぉ」「修正前はインスタンス変数の中で作られていたからインスタンスがあるとオブジェクトがずっと残っちゃっていたけど、修正後は生成をprivateメソッドの定義に移したからメソッドが終わればオブジェクトが解放される、だからメモリ使用量が減ったと」「なるほど」「さらにEMPTY_ARRAYの場合は生成せずに即戻るようになったので、ここで速くなったんでしょうね: @ifとか@unlessを使わない場合は生成不要ですし☺️」「@ifとか@unlessはめったに使わないでしょうし😋」
⚓テーブル名をRegexp.escapeで処理
# activerecord/lib/active_record/relation/query_methods.rb#L1255
def table_name_matches?(from)
- /(?:\A|(?<!FROM)\s)(?:\b#{table.name}\b|#{connection.quote_table_name(table.name)})(?!\.)/i.match?(from.to_s)
+ table_name = Regexp.escape(table.name)
+ quoted_table_name = Regexp.escape(connection.quote_table_name(table.name))
+ /(?:\A|(?<!FROM)\s)(?:\b#{table_name}\b|#{quoted_table_name})(?!\.)/i.match?(from.to_s)
end
そういえばMSSQLではテーブル名などで通常使えない文字(空白など)がある場合に[]でも囲めるのでした。
| RDBMS | オブジェクト識別子 |
|---|---|
| Oracle | "で囲む |
| PostgreSQL | "で囲む |
| MySQL | バッククォートで囲む |
| MSSQL | "、バッククォート、[]で囲む |
つっつきボイス:「ああ、Microsoft SQL Serverのテーブル名やカラム名を囲む[や]をエスケープしたのね☺️」「え?😅」「[や]を使ってるの見たことありませんけどMSSQL使いには常識なのかな?🤔」
⚓マルチDBのRelationでconnected_toが強制的にレコードを読み出すよう修正
# activerecord/lib/active_record/connection_handling.rb#L258
def swap_connection_handler(handler, &blk) # :nodoc:
old_handler, ActiveRecord::Base.connection_handler = ActiveRecord::Base.connection_handler, handler
- yield
+ return_value = yield
+ return_value.load if return_value.is_a? ActiveRecord::Relation
+ return_value
ensure
ActiveRecord::Base.connection_handler = old_handler
end
connected_toブロックがリレーションを返してそれをinspectしなかった場合や、返す前にリレーションを読み込んだ場合、データベースにクエリをかける前にブロックが終了する。これが原因で、クエリ対象のデータベースコネクションが正しくなくなる。
その結果、レコードがreplicaではなくprimaryから取得され、データベースのパフォーマンスに影響する可能性もある。
リレーションはデータベースにlazyにクエリをかける。以下のようにブロックからリレーションを返すと、posts.firstのクエリはlazyかつブロックの外で実行されるので、writingコネクションから送信される。
posts = ActiveRecord::Base.connected_to(role: :reading) { Post.where(id: 1) }
(
to_aのように)ブロック内でリレーションを読み込むクエリではリレーションのレコードをeager loadingするのでこのバグは顕在化しない。
修正後のconnected_toは、戻り値がRelationかどうかをチェックして、該当の場合はloadを呼び出すようになった。
同PRより大意
つっつきボイス:「Rails 6のマルチプルデータベースはいろいろややこしそう😅」「eager loadingしなかった場合にクエリを出さずに終わっちゃうことがあったとは😳」「Post.where(id: 1)は本来readingロールのレプリカから読んで欲しかったのに、クエリがlazyなのでconnected_toのスコープを抜けてからposts.firstするとwritingロールのプライマリから取ってきてしまってた、というバグか😇」「これを踏むのは大規模なマルチDBでしょうけど、パフォーマンスチェックしてあれ?と思ったときに備えて、このあたりの挙動は知っておく必要ありそう🤔」
⚓Rails
⚓Vue+Rails 6でのCRUD
つっつきボイス:「RailsとVue.jsで普通にCRUDを作ってみたという感じですね☺️: rails newに--webpack=vue付けて、VuetifyはVueがやってくれて、とか」「やってみた系の記事かな」「Vuetify.jsはMaterial Designフレームワークみたいです」
「これも記事に出てくるaxiosというJSライブラリはPromiseベースみたい」「最近はasync/awaitが広まってきたせいか、まだPromise使ってんの?みたいな風潮にちょっとなってたりするのかななんて😆」「😆」「自分がPromiseの謎記法に慣れちゃったのもありますが☺️」
// 同記事より
#app/javascript/packs/components/user.vue
getUser(item) {
axios.get(`https://localhost:3000/${item.id}`)
.then(response => {
this.dessert = response.data;
})
.catch(error => {
console.log(error);
})
}
# 同記事より
#app/controllers/users_controller.rb
def show
@user = User.find(params[:id])
render json: { data: @user, status: :ok, message: 'Success' }
end
参考: Async/await
⚓Railsビューのパフォーマンス最適化(Ruby Weeklyより)
「こちらはビューのパフォーマンス記事」「Railsで重くなるのはたいていビューかデータベースですね🧐」
「そういえばLaravelのテンプレートエンジンがすごく重くなるときがあるみたいな噂聞きましたけど、エンジンの名前何でしたっけ?」「Bladeかな」「そうそうBlade、MVC系のフレームワークはビューテンプレートあたりの書き方次第では重くなることもありますし、Railsのビューもちゃんと書けば速いけど気をつけないとですね☺️」「ですね」
「ビューで重たいメソッドを気軽にeachで書いちゃうと行数に比例して遅くなりますし: データベースのN+1ではないビューのN+1的なヤツですが」「😆」「気をつけてないと割とこういうの書いちゃうんですよね: 管理画面ぐらいなら別に構わないかなとも思いますけど😆」
同記事目次より:
- データベースクエリの見直し
- HTMLリロードを避ける
- Turbolinks
- Ajaxリクエスト
- WebSockets
- キャッシュを効かせる
- ビューのキャッシュ
- データベースクエリのキャッシュ
- データベースのインデックス
- まとめ
⚓ドロップダウンボックスをチェックボックスに変更するまでの作業(Ruby Weeklyより)
なぜかRuby Weeklyでのタイトル「Changing a UI Control and DB Schema on a Production Rails App」からだいぶ変わっています。
つっつきボイス:「ああ、ビューでこういう変更が入ったときにこんな作業が発生したぜという記事😆」「has_oneだったのをhas_manyにした的な」
同記事より
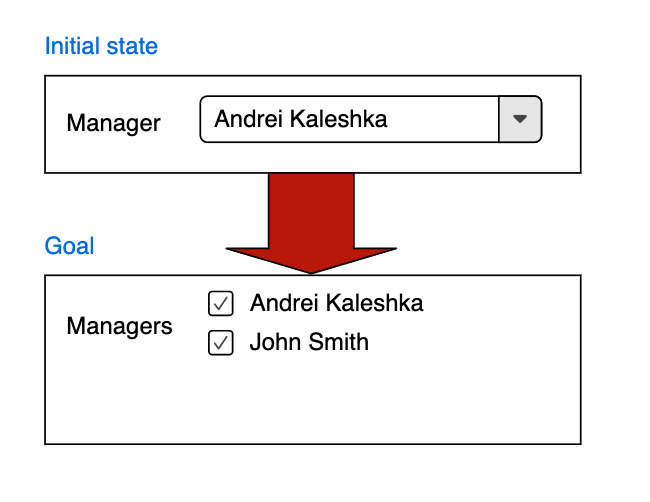
「こういう変更よくありますよね😆」「あるある😆」「誰もがやったことある変更😆」「カテゴリは最初1個表示だったのに複数に変えて欲しいとか😆」「最初に言ってくれれば...😢」「慣れてくると、いずれhas_manyになるだろうみたいな勘がビビッと働いてhas_oneで書いとくこともありますけど😆」
⚓OpenAPIとcommittee gem
- 元記事: committee×OpenAPI×RailsでスキーマファーストなAPI開発 | GiFT(ギフト)株式会社
- リポジトリ: interagent/committee: A collection of Rack middleware to support JSON Schema. -- RackベースのJSONスキーマサポート
つっつきボイス:「BPS社内で話題になっていたので」「最近OpenAPIでAPI設計しようかみたいな話がちらほら出たりしてますね☺️」
「OpenAPIは以前Swaggerと言われてたものですけど、使ったことあります?」「使ってません😆」「前は使ってた?😆」「使おうかなと思って調べたところまでです😅」「まあ今やるならSwaggerよりOpenAPIの方でしょうね☺️」「Swagger 3.0がOpenAPIということみたい🤔」
参考: 本当に使ってよかったOpenAPI (Swagger) ツール | Future Tech Blog - フューチャーアーキテクト
参考: OpenAPI Specification | Swagger
⚓OpenAPIの使い所
「Swagger使うとドキュメント書きで幸せになれるらしいと聞いて調べました😆」「まあどこまでドキュメント化するかとかも含めて、そんな夢のツールというほどでもない🤣」「🤣」「ただAPI仕様書のフォーマットという意味ではなかなかいいと思いますね😋」「おぉ」「ExcelでAPI仕様書書かなくていいですし😆」
「OpenAPIは、CRUDベースでJSON受け取ってJSON返すだけのシンプルなAPIを記述するにはいいんですけど、ものすごく複雑なJSON受け取って複雑なJSONを返すようなAPIだと...ね😇」「😆」「URLのエンドポイントは1個なのに、カラムの内容に応じてレスポンスの形式まで変わっちゃうようなAPIとか😆」「😆」「そういうのをOpenAPIで記述しようとすると超ツラい😭」「逆にRailsのようなRESTfulなAPIなら、OpenAPIでとてもキレイに書けます❤️」
「あとOpenAPIのありがたい点は、書式がそれほど厳しくないことですね😋」「へぇ〜」「少しぐらい雑に書いてもドキュメント生成してくれるので、厳密に書くのを諦めつつも使うことがたしかできたと思います」「ふむふむ」「OpenAPIで自動生成されるスタブのAPIサーバーがどのぐらいちゃんと動くのかは知りませんけど😆、書式が決まっていてExcelを使わないという点でOpenAPIは好きですね🥰」
⚓loaf: Railsでパンくずリスト(Ruby Weeklyより)
同リポジトリより
つっつきボイス:「いわゆるパンくずリストの新しめのgemだそうです」「ローフ?」「パン一斤を指してa loaf of breadという言い方をするので、それをもじったっぽい」「なるほど、breadclumbbreadcrumb(パンくず)だけに😆」
# 同リポジトリより
class Blog::CategoriesController < ApplicationController
breadcrumb 'Article Categories', :blog_categories_path, only: [:show]
def show
breadcrumb @category.title, blog_category_path(@category)
end
end
「どことなく見たことのあるDSL↑😆: こういうパンくずリストgemって他にも相当昔からあったな〜、あgretelだ↓」「ヘンゼルとグレーテルの話そのまんま😆」
同リポジトリより
「ありゃ〜gretelはメンテ終わってるし😇」「WilHall/gretelがactiveって書いてあるけどこっちも1年ほど更新されてないっぽい...」「それでloaf作ったのかも?🤔」「移行先の★が少ないということは最近もしかするとパンくずリストってあんまり使われてなかったりして😆」「まあパンくずリストなら自分で実装してもいいくらいですし😆」
追記(2020/02/04): loafの歴史も結構長いようです🙇。
「ちなみにgretelはビューにコードを書くけど、loafはコントローラに書くところが違ってますね、と思ったらloafはビューにも書けるらしい😆」
「パンくずリストってきれいに設計するのが割と難しいですよね😅」「SEO的な理由で欲しいと言われたりとか」「今どきのWebサイトってツリー状にきれいに階層化されてることってあまりありませんし、パンくずリスト付けると、入ってきた動線と違うパスが表示されたりして何となく気持ち悪いとか😆」「あまり気にしてませんでしたけど気持ち悪さはわかります😆」「パンくずリストって、気持ちとしては自分が辿ってきた動線を戻れるように表示されて欲しいのに、今どきはあらゆるところからあらゆるところへ戻ったりしますし😆」「😆」「なのできれいなパンくずリストにするのは割と諦めの境地かも😇」
「ちなみにパンくずというと自分はMOTHER1思い出しますが😆」
参考: MOTHER1小ネタ
⚓その他Rails
つっつきボイス:「Rails 6のマルチDBやってみたスライドを見つけたので」「本番で使うとは勇者😆」「自分が今RailsでマルチDBやるなら絶対switch_point使いますけど😆(ウォッチ20180723)」「上の『先週の改修』にあったレプリカからプライマリに切り替わっちゃうあたりとかも含めてまだ改良の余地ありそうですし、個人アプリで試すならともかく本番に入れる気にはまだなりませんね😅」
同リポジトリより
今日公開したQiita記事です。僕にテストコードをコードレビューさせると、だいたいこのへんの話をツッコまれますw
「アプリケーションが壊れているのに検知できないテストコード」を書かないようにするための、べからず集 https://t.co/CHjjnaj5fq #Qiita
— Junichi Ito (伊藤淳一) (@jnchito) January 29, 2020
つっつきボイス:「jnchitoさんのテスト記事です」「こういう記事を書いたということは、アサーションのないテストとかを実際に目にしたんでしょうね...」
「『エラーを検出できないテストを書かない』、これやられるとテストの工数がまるまる無駄になってしまいますし😢」
「『〜ではないことだけをテストしない』、正常系と異常系を両方テストしないとたいてい見落としが発生しますね😇」「どんなに自明だと思っても両方書かないと」
「境界値テストはどこまでやるか悩ましいけど必要ならやらないと」「年齢だったらわざとマイナスの数値入れるとか😆」「まそこまでやるかどうかですが😆」
「『呼び出されないlet』もやめて欲しいヤツ: 使わないテストデータが残ってると消していいかどうかもわからなくて超ツラい😢」
「『絞り込みの甘いテスト』もあるある😆」「テストコードを書いたときはうまく動いていても、機能やテストを追加すると絞り込みが甘くなったりすることがたまにありますね☺️」「たとえばcountして数を確認するテストなんかは1種類だけ書いてもこういうのを検出できないことがあったりするので、2種類書いておけば片方だけ落ちて検出できたりとか」「ふむふむ」
「not系のテストは、気をつけないと必ずパスしちゃうテストにたまになったり😆」「『テストファーストは必須でない』もわかる!」「自分はTDDってそれほど好きじゃないんですけど、テストを失敗させれば少なくともそのテストが動いていることは確認できるので、これも同意ですね☺️」
「『DRYを追求しない』も大賛成」「DRYにされるとコードを足したり削ったりしにくい😭」「『ループ処理を使わず、愚直にユーザー名をベタ書きする』も賛成!」「テストコードは変にロジカルにしないで基本ベタに書きましょう🧐」「テストコードにリテラルがんがん書いてOK😋」
「カバレッジといえば、simplecovの設定ミスっててカバレッジがちょっと漏れてたりすることあった😆けど最近は見ないかな〜」「最近のRubyだとコードから行単位で情報取れたりするので精度上がってそう😋」「テストコードがあってもそれ自体が検証されてなくて後でメンテする人がかえって泥沼になった事件あった🤣」「テストが検証されてなかったとか普通思いませんし🤣」
「どのエントリも納得😋」「jnchitoさんは、こういう当たり前のことをみっちり書いてくれるのがとってもありがたい🙏」
前編は以上です。
おたより発掘
ビュー最適化、パンくずリストあたりの話が良かった
週刊Railsウォッチ(20200203前編)Railsの各種高速化コミット、OpenAPIの使い所、パンくずリストgem loaf、Railsビュー最適化ほか https://t.co/EYJRnTw6wJ
— あっきー🍺 (@kuronekopunk) February 4, 2020
バックナンバー(2020年度第1四半期)
週刊Railsウォッチ(20200128後編)もう一つのgemマネージャgel、”Did you mean”の仕組みを追う、DXOpalでブラウザゲームほか
- 20200127前編 Railsでキーワード引数warning退治始まる、ライブラリとフレームワークの違い、ShopifyのRails高速化記事ほか
- 20200121後編 RubyKaigi 2020受付開始、RubyGemsとBundlerの今後、ファイル同期ツールMutagenほか
- 20200120前編 福岡でも公開つっつき会、Railsのconnection_specification_nameでprimaryという名前が非推奨に、structure.sqlとschema.rbほか
- 20200115後編 Ruby 2.7関連情報、Bootstrap 5は今年前半リリースか、PostgreSQLでやってはいけないリストほか
- 20200114前編 config_forのbreaking change、Active Storage variantをDBでトラッキング、SprocketsとWebpackの違いほか
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやはてブやRSSやruby-jp Slackなど)です。
