前回: (6/16)機械学習とニューラルネットのトレーニング
🔗 ChatGPTのしくみとAI理論の根源に迫る:(7/16)ニューラルネットのトレーニング法と秘技(翻訳)
ニューラルネットをトレーニングする技術は、特にこの10年間で著しく進歩しました。これはまさしく、一種の職人芸であると言えるでしょう。そして運が良ければ、そこで起きていたことは実は「科学的に説明可能である」という片鱗に触れることもあるでしょう(特に後から振り返ってみるとそう思えてきます)。
しかしニューラルネットにおける発見は、ほとんどの場合、理論ではなく、おびただしい試行錯誤の末に見出されたものであり、そこにニューラルネットをいかに扱うべきかという知見が少しずつ加わる形で、徐々に築かれてきたものなのです。
これらの知見には、いくつもの重要な点が含まれています。
- どんなタスクにどんなニューラルネットのアーキテクチャを使うのが適切なのか
- 極めて重要: ニューラルネットをトレーニングするときに使うデータを、そもそもどうやって手に入れるか
そして、今どきニューラルネットをゼロからトレーニングする必要性はますます下がっています。今や、既に学習済みのニューラルネットを直接取り入れることも可能ですし、その学習済みニューラルネットからトレーニング用のサンプルを生成することも可能です。
「タスクの種類がまるで違う場合は、使うニューラルネットのアーキテクチャもそのタスクに応じて変えないといけないんでしょ?」と思われるかもしれません。しかし実際には、タスクの種類が相当違っていても、ニューラルネットのアーキテクチャは同じで済むことが既に判明しています。そして実際に、ニューラルネットは「人間が行うような情報処理」をかなり汎用性の高い形でキャプチャすることが可能なのです。
原注
これは、ある意味で普遍計算(universal computation)(もしくは私が打ち立てた計算等価性の法則(Principle of Computational Equivalence)))という壮大なものを思わせる点もありますが、むしろ、後ほど議論するように、ニューラルネットで行わせる典型的なタスクが「人間が行うようなタスク」であることを色濃く反映していると思われます。
ニューラルネット研究の初期には、「ニューラルネットに行わせるタスクはなるべく小分けにして処理すべき」という考え方が主流でした。たとえば音声会話をテキストに変換するタスクは、「音声で何を喋っているかを解析する」という前処理を行い、それからテキストを品詞分解するべきだと考えられていました。
ところが、ニューラルネット研究が進むに連れて、少なくとも「人間が行うようなタスク」については、研究者がそうやって処理を専用のコンポーネントに小分けにしてあげるよりも、処理の途中で必要な特徴(feature)やエンコーディング(encoding)といった要素については、問題を一括してニューラルネットに食べさせる形で中間のニューラルネット自身に「発見させる」方が結果がよいことが判明してきました。
ニューラルネットに専門機能のための複雑なコンポーネントを導入することで、「特定のアルゴリズムに沿った思考法」を実装してみてはどうか、というアイデアも検討されましたが、このアイデアは間もなく、ほぼ無意味であることが判明しました。
それよりも、ニューラルネットを構成するコンポーネントはごくシンプルに保っておき、そうした特定のアルゴリズム的思考のための(ものであろう)専門機能は、人類にはまだ伺いしれない「自己組織化(organize themselves)」によって実現する方が、ずっと有効だったのです。
原注
ニューラルネット方面ではコンポーネントに分割するといった「構造化のアイデア」が通用しない、などと言いたいのではありません。
たとえば、局所的に相互接続されるニューロンを2次元配列化するといった構造化のアイデアは、少なくとも画像処理の最初の数段階では極めて有効であることは確かです。
また、「シーケンスを振り返る」手法、すなわちシーケンスや系列データを遡って参照することに特化した逆方向の接続パターンを導入する手法も、後ほど述べるように、ChatGPTなどで人間の言語を扱うときに有効であると考えられています。
しかし、ニューラルネットの重要な機能のひとつは、ニューラルネットが扱っているのはあくまでデータのみであることなのです(実はコンピュータというものがそうであるように!)。
現時点のニューラルネット、具体的にはニューラルネットをトレーニングする現時点の手法においては、数値に特化したさまざまな配列を扱っています。しかしこれらの配列は、処理の過程が進むに連れて、まったく異なる形に再配列することが可能なのです。
たとえば、前の章で用いた、数字の画像を識別するのに使われるニューラルネットは、画像識別の最初の段階(下の模式図の一番左にある緑の正方形)では、まるでビットマップを写し取った「画像」のような2次元配列になっており、処理が図の右方向に少し進むと、すぐに「厚みを増します」。しかしさらに処理が進むと1次元配列に"集約"され、出力される配列には、最終的にさまざまな数字(1や2など)を表す要素が含まれます。
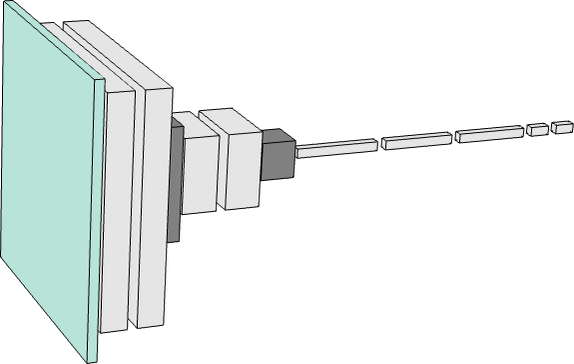
しかし、あるタスクで必要なニューラルネットの規模がどのぐらいになるかを、どうやって見積もればよいでしょうか?これはまさしく(理論ではなく)職人芸に属する作業であり、ある意味では「そのタスクがどのぐらい困難であるか」をいかに見抜くかが鍵となります。
しかし、人間が行うようなタスクが対象となると、そのようなタスクの難易度を見積もるのは極めて難しいのが普通です。
もちろん、人間が行うようなタスクを、コンピュータプログラムでうまいこと「機械的に」実行可能な、システマティックな実行方法がどこかに存在する可能性ぐらいはあるでしょう。しかしながら、あるタスクについて、少なくとも「人間が行うのと同じレベル」でやすやすと実行できるような裏技もしくはショートカットと思えるものが「都合良く」存在するかどうかを知るのは困難なのです。
原注
何らかのゲームを「機械的に」解こうとしたら、いわゆるゲーム木(game tree)をすべて列挙しつくす必要があるかもしれませんし、実はもしかすると「人間レベルのプレイ」をずっと楽に実現できる裏技的なヒューリスティクス(heuristic: 発見的方法)が見つかるかもしれません。
小さなニューラルネットでシンプルなタスクを実行させる場合には、「解にはたどり着けない」ことが明確にわかる「こともあります」。
たとえば、前回記事で見たようなタスクを、以下のような8種類のニューラルネットを用いて解く方法を可能な限り最適化した結果を以下に示します。
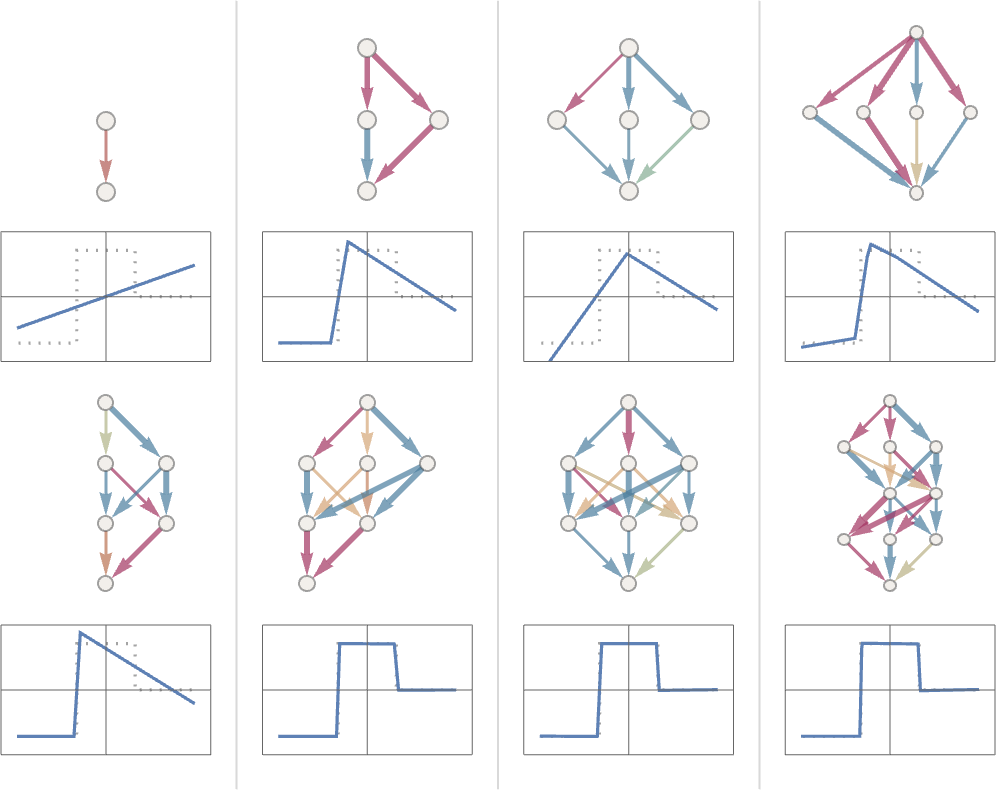
図の上半分にある4つのニューラルネットと、図の下半分にある最も左のニューラルネットで示されているように、ニューラルネットが小さすぎると、欲しい関数を再現できなくなることがわかります。
しかし幸いにも、ニューラルネットの規模がある程度以上に大きくなると、少なくとも十分な数のサンプルを使って十分長い時間トレーニングしていれば、このような問題は起きなくなります。
ちなみに、これらの図はニューラルネット界隈で代々受け継がれている秘技(lore)の一部を示しています。
つまり、中間に「スクイーズ(squeeze)」と呼ばれるくびれが存在して、あらゆるものが強制的により少数の中間ニューロンを通過する形になっていれば、多くの場合ネットワークの規模を小さくしても問題ないということです。これが「秘技その1」です。
原注
「中間層なし」の、いわゆる「パーセプトロン」ネットワークは、基本的に線形関数しか学習できませんが、中間層が1つでも存在すれば、少なくとも十分な数のニューロンがあれば、原理的には任意の関数を任意に近似することが可能です。
ただし、適切にトレーニングできるようにするには、通常、何らかの正則化(regularization: 過学習を防ぐ)または正規化(normalization: 学習を安定させる)を行います。
さて、何らかのニューラルネットで「アーキテクチャにはこれを使おう」とめでたく決まったとします。
次の課題は、そのニューラルネットをトレーニングするのに使うデータをどうやって手に入れるかです。実際、ニューラルネットや、一般的に言う機械学習を実用化するうえで苦労しがちなのは、トレーニングに必要なデータをどうやって手に入れ、どうやってトレーニングの準備を整えるかという部分です。
多くの場合(ここでは教師あり学習(supervised learning)を指します)、「どんな入力を与えたら、どんな出力を得られるべきか」が明確になっているサンプルデータが大量に欲しくなるものです。
つまり、たとえば画像とタグ付けという応用例で言うと、画像とそれに対応する「"これはXXの絵である"ことを示すタグ」などを学習させたいでしょう。そのために必要なタグ付けをまともに行おうとすると、大勢の人間による労力を注ぎ込む形で明示的に行わなければなりません。
しかしうまく工夫すれば、世の中に転がっている既存のデータをちゃっかり流用したり、何らかの形で代用できることも少なくありません。
たとえば、Webページの画像に付いているalt属性を使うとか、分野によっては、動画に付いてくるクローズドキャプション(closed caption: セリフに加えて物音や状況説明なども含む字幕)を使う手もあるでしょう。翻訳用のトレーニングであれば、多言語化されたWebページから得られるデータや、複数言語バージョンが存在するドキュメントを使ってもよいでしょう1。
さて、何らかのタスクを学ばせるのに必要なデータをどれだけの量与えてやれば、ニューラルネットをまともにトレーニングできるのでしょうか?
これまでと同様、この見積もりを原理に基づいて導き出すのは困難です。
もちろん、「転移学習(transfer learning)」と呼ばれるテクニック2を用いて、別のニューラルネットワークで学習済みの重要な特徴のリストを文字通り「転移」させれば、必要なデータ量を劇的に減らすことは可能です。
しかし一般に、ニューラルネットを十分にトレーニングするためには、やはり「なるべく大量のサンプルデータ」を与えてやる必要があります。さらにタスクによっては、サンプルデータを繰り返し繰り返し与えてやることが、ニューラルネットにおける重要な「秘技その2」となっています(実際、ニューラルネットにすべてのサンプルを繰り返し繰り返し与えるのは定番の手法です)。
そうしたトレーニングの1ラウンドはエポック(epoch)とも呼ばれていますが、ニューラルネットのステート(state: 状態)は、エポックのたびに少しずつ変わります。また、特定のサンプルデータを何らかの形で「頑張って思い出させる」ことが、そうしたサンプルに関する記憶の定着において有効であることもわかってきました。
原注
このことは、人間がものごとを記憶するうえで反復練習が有用であることとおそらく似ているでしょう。
しかし、漫然と同じサンプルデータを何度も何度も与えてやるだけでは、うまくいかない場合も多いのです。そういう場合は、ニューラルネットにサンプルデータを少しずつ異なるバリエーションを与えてやることも必要になります。実は、このとき与えるバリエーションは、十分手間ひまをかけて精査して整えたデータでなくても構いません。これはニューラルネットの「秘技その3」です3。
たとえば、基本的な画像処理であれば、画像をほんの少し変えて与えてやるだけで、事実上「新しい画像情報」としてニューラルネットのトレーニングで使えるようになります。また、自動運転車のトレーニングに使いたい運転風景の動画がもっともっと必要なのに足りなくなってきたら、現実世界よりも再現度のユルいビデオゲームのようなモデル環境を代わりに与える方法も、立派に通用するのです。
画像・動画系AIのトレーニング方法については以上のような感じですが、さて、ChatGPTのような言葉を扱うチャットAIのトレーニングについてはどうでしょうか?
実は、言葉を扱うチャットAIでは「教師なし学習(unsupervised learning)」という嬉しい手法が使えるため、トレーニングに使うサンプルデータを手に入れるのがぐっと楽になるのです。
第1章で学んだように、ChatGPTの主なタスクは「文章の前半を与えられたときに、その続きにどんなトークンが来るかを次々に見つけていく」ことだったのを思い出してください。
ということは、チャットAIをトレーニングするためのサンプルデータが欲しければ、普通の文章を手に入れて、その一部を取り出して末尾を隠してしまえば、それだけでトレーニング用サンプルデータの「入力部分」になり、末尾を隠していない文全体が学習すべき「出力部分」としてそのまま使えるのです。
これについて詳しくは後述しますが、ここで重要なのは、ChatGPTのようなチャットAIをトレーニングするときは、画像のタグ付けのときのように人力でタグを付けるという追加作業を必要とせず、与えられたサンプルテキストを直接学習できることなのです。
さて、 ニューラルネットに実際に学習させるときは、どんな点が肝心なのでしょうか?最終的に大事なのは、ニューラルネットに与えたトレーニング用サンプルデータの特徴を最大限うまく捉えられるさまざまな「重み(weight)」をどのようにして決定するか、です。
そして、適切な重みを決定するための細かな選択肢や「ハイパーパラメータ設定(hyperparameter settings)」は大量に存在します(重みは「パラメータ(parameter: ここでは学習で決定される値)」の一種とみなせるので、こう呼ばれることもあります)。
原注
たとえば、損失関数(loss function)ひとつ取っても、「2乗和」や「絶対値和」などさまざまな損失関数を選択できますし、損失を最小化する手法も、「重み空間内の各ステップでどれだけ移動するか」など、さまざまな手法を選べます。また、最小化したい損失をステップごとに見積もるときに、サンプルデータを「いくつずつ」のバッチ(batch)で与えるのが適切かという問題もあります。
また、我がWolfram言語で行っているように、機械学習(machine learning)の手法を適用することで機械学習そのものを自動化し、ハイパーパラメータなども自動設定することも可能です。
しかし最終的には、損失が減っていく様子をグラフで追って確認すれば、トレーニングの進捗を特徴づけることは可能です。我がWolfram言語に備わっている小規模トレーニングのプログレスモニターで表示される以下のグラフのように。
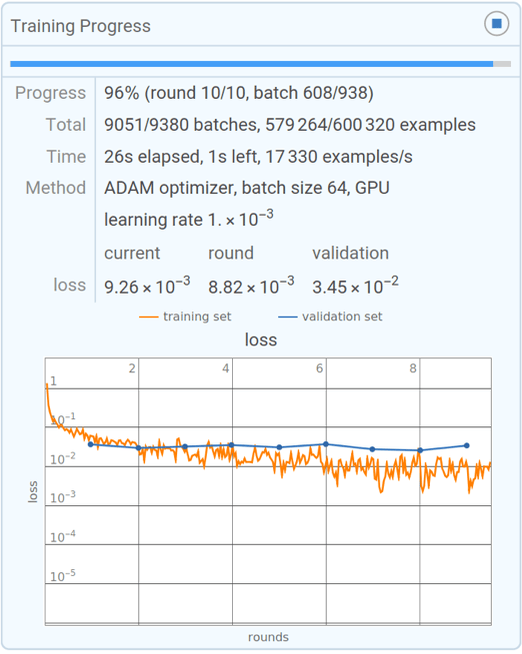
損失の減り方は、「開始後しばらくの間は減り続けるが、最終的には何らかの一定の値に落ち着く」というのが典型的なパターンです。落ち着き先の値が十分小さければ、トレーニングは成功したと言えるでしょう。逆に値が小さくなってくれない場合は、ニューラルネットのアーキテクチャを選び直すところからやり直す必要があるかもしれません。
さて、この「学習曲線(learning curve)」が落ち着くまでにどのぐらいかかるかを予測できるでしょうか?この手のデータによくあるように、ニューラルネットのサイズやデータ量に依存する、べき乗則に近いスケーリング関係になるようです。
しかし、ニューラルネットのトレーニングは一般に困難が伴いますし、膨大な計算量を要求されるのが常です。しかも現実問題として、その計算量の大半を占めているのは、数値の配列に対する演算です。幸い、こういう単純な計算を大量に実行するのはGPUが得意とする分野です。すなわち、ニューラルネットをトレーニングするときは、GPUをどのぐらい豊富に使えるかで制約を受けるのが普通です。
原注
今後、ニューラルネットをトレーニングしたり、ニューラルネットが行えることを一般的に可能にしたりする、何らかの画期的な方法が出現する可能性はあるでしょうか?私は、ほぼ確実にそうなると見込んでいます。
ニューラルネットの基本的な考え方は、シンプルなコンポーネント(コンポーネントの作りには本質的に何の違いもありません)を大量に用いて、ある種の柔軟な「コンピューティングファブリック(fabric: 織物、組織)」とでも言うべきものをこしらえ、このファブリックを進むに連れてインクリメンタルに変更する形で、サンプルデータから学習可能にするというものです。
現在のニューラルネットでは、このインクリメンタルな変更を実現するために、実数に対する微積分(calculus)というアイデアを用いています。しかし、実はこの微積分で使われる数値の精度(つまり小数点以下の桁数の多さ)は重要ではなく、現在の手法ですら8ビット以下で十分であろうということが近年明らかになりつつあるのです。
セルオートマトン(cellular automata)のような計算システムは基本的に大量のビットをパラレルに処理しますが、上のようなインクリメンタルな変更がそうした計算システムでどのように行われるかは、これまで定かではありませんでした。しかし今や、これが不可能であると考える理由はありません。
実際、2012年に深層学習(deep learning)で起きたブレークスルー(第6章)とかなり似たような感じで、インクリメンタルな変更が、シンプルなケースよりも複雑なケースの方が実質的にやりやすくなる可能性があるのです。
ニューラルネットは、おそらく人間の脳も少しはそうであるのと同じように、ニューロン同士のつながり(=ネットワーク)は本質的に固定された形でセットアップされています。そして変更されるのはネットワークではなく、ニューロン同士の接続の強度(=重み)の方です(ただし若い脳では、かなりの個数の新しい接続が形成される可能性があります)。
しかしこの固定セットアップは、生物学の研究では便利かもしれませんが、私たちが必要とする機能を実現するうえで本当にこれがベストなのかについては何ひとつわかっていません。もしかすると、固定ネットワークよりも、(私の主催するPhysics Projectを思わせるような)ネットワークをじわじわと書き換えるような方式の方が最終的に優れている可能性だってあるのです。
しかし現時点では、既存のニューラルネットのフレームワーク内ですら、ある重大な制約が存在しています。
現在ニューラルネットに対して行われているトレーニングは,基本的に(パラレルではなく)シーケンシャル(sequential: 逐次処理)であり、与えるサンプルデータのひとかたまり(バッチ: batch)ごとの効果を逆方向に伝搬させる形で4ニューラルネットの重みを更新しています。そして実際に、現代のコンピュータハードウェアでは、たとえGPUのサポートを考慮したとしても、ほとんどのニューラルネットはトレーニング中ほとんどの間「アイドリング(idle: 何もしていない)」状態であり、ニューラルネットの更新は一度に1箇所に限られてしまうという極めて非効率な処理にならざるを得ません。ある意味、その原因の1つは、現代のコンピュータではCPU(もしくはGPU)とメモリが別の場所に置かれる傾向があるためです。
しかし人間の脳はコンピュータの場合と作りが大きく異なるはずであり、脳の「記憶要素(つまりニューロン)」は単なる記憶素子ではなく、潜在的にはそれ自体が計算要素でもあるはずだと考えられています。今後コンピュータのハードウェアの脳と同じようにセットアップ可能になれば、トレーニングを現在よりも遥かに効率よく進められる「かもしれません」。
次回: (8/16)ニューラルネットは「大きければ大きいほどいい」のか?
関連記事
- 訳注: これらの手法は技術的に可能ではありますが、通常は著作権やライセンスについて別途確認が必要です。 ↩
- 訳注: 転移学習の手法には、「特徴抽出器として利用する(学習済みのニューラルネットの前半部分を流用し、後半部分を新しいタスク向けに再学習させる)」、「既存のニューラルネットにある重みの初期値を流用して微調整する」「画像を特徴ベクトルに変換して別のカテゴライザの入力として流用する」といったものがあります。 ↩
- 訳注: これは画像データで言うなら色や向きや形などが少しでも違っていればバリエーションとして使えるという意味です。しかしおそらく、現代のLLM、特にコーディングAI用のLLMであれば、人力を投入して相当洗練されたバリエーションを用意して与えてやる必要があるだろうと推測されます。また、医療診断AIや創薬AIなど、人命に関わる分野では、常に「精査された本物のデータ」を使わなければ意味がありません。 ↩
- 訳注: これが、深層学習で多用されているバックプロパゲーション: 誤差逆伝播法という学習アルゴリズムです。 ↩
概要
原文サイトのCreative Commons BY-NC-SA 4.0を継承する形で翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。原文が長大なので、章ごとに16分割して公開します。
スタイルについては、かっこ書きを注釈にする、図をblockquoteにするなどフォーマットを適宜改善し、文面に適宜強調も加えています。
元記事は、2023年2月の公開時点における、ChatGPTを題材とした生成AIの基本概念について解説したものです。実際の商用AIでは有害コンテンツのフィルタなどさまざまな制御も加えられているため、そうした商用の生成AIが確率をベースとしつつ、確率以外の制御も加わっていることを知っておいてください。
本記事の原文を開いて、そこに掲載されている図版をクリックすると、自分のコンピュータでもすぐに実行して試せるWolfram言語コードが自動的にクリップボードにコピーされるようになっています。
コモンズ証 - 表示 - 非営利 - 継承 4.0 国際 - Creative Commons