こんにちは。yoshiです。夏のTechrachoフェア2022ということで、夏とは何の関係もない記事を書いていこうと思います。
業務ではC++をやっていながら前回、前々回にTechrachoで書いた記事に引き続きRustをやっていく訳ですが、定期的に炎上しがち(?)なオブジェクト指向の話です。みなさん、オブジェクト指向は好きですか?
オブジェクト指向って何だろう?
A. なんもわからん
なんて言ってしまったら話が終わってしまうのですが。
歴史的な話をするとオブジェクトという用語はSimulaが初出で、オブジェクト指向はアラン・ケイがSmalltalkで導入したもの、という話になりますが、一方でビャーネ・ストロヴストルップがC++に導入した「カプセル化・継承・ポリモーフィズム」の組み合わせのことを指すことが多く、SmalltalkのそれとC++のそれにも違いがあるので定義が定まらない概念でして、それ故「オブジェクト指向とは○○である」みたいな話はやりづらいのです。
まあ私もC++を母語として長年やってきたので、ここは「オブジェクト指向プログラミング(OOP)とは、カプセル化・継承・ポリモーフィズムを利用したオブジェクトの組み合わせで行うプログラミングのことである」という定義で話を進めていこうと思います。C++以外にも、Javaなどがこの定義におけるOOP言語とされることが多いと思います。
Rustはオブジェクト指向?
A. わからん
「お前はそればっかりだな」とお思いかもしれませんが、Rustの聖典であるThe Rust Programming Language にもこう書いてあります。
Many competing definitions describe what OOP is, and by some of these definitions Rust is object-oriented, but by others it is not.
https://doc.rust-lang.org/book/ch17-00-oop.html
日本語訳もあります。
多くの競合する定義がOOPが何かを解説しています; Rustをオブジェクト指向と区分する定義もありますし、しない定義もあります。
https://doc.rust-jp.rs/book-ja/ch17-00-oop.html
ちなみにWikipediaを見るとこう書いてあります。

うーん、これはオブジェクト指向言語!
さておき、Rustは後発言語のアドバンテージとして、先発言語の良い部分を取り込み、良くない部分を取り込まないように設計されています。なので、OOPの特徴とされる「カプセル化・継承・ポリモーフィズム」に関しても、良い部分を取り込んで良くない部分を取り込まないようになっています。
したがって、オブジェクト指向批判で頻出のいくつかの問題はRustにおいては解決されているのですが、しかしそのためにRustはオブジェクト指向パラダイムをすべて取り込んでいるわけではないので、そうするとそれはオブジェクト指向と言えるのだろうか?ということになってしまうのですね。
改めて個人的な意見を言うと、私はオブジェクト指向というものは「オブジェクト指向というパッケージ」で語ることにあまり意味はないと思っています。「カプセル化・継承・ポリモーフィズム」という概念それぞれには重要な示唆も含まれているものの、また「カプセル化」「継承」「ポリモーフィズム」というそれぞれの概念ももう少し細分化して考えるべきだと思っています。オブジェクト指向を理解・分解・再構築するのです。オブジェクト指向なんもわからんけど。
カプセル化を分解する
カプセル化とは?
オブジェクトは、一般に複数のデータと、データを操作するメソッドを組にしたもの、と説明されます。なので大抵のオブジェクトはデータを持っています。
例えばC言語では複数のデータの組を作るには構造体を使いますが、C言語の構造体は中身が丸見えになっています。
データ構造の中身が見えるのは場合によっては利点ですが、不都合が発生するケースもあります。特に、書き換えが可能な場合が顕著です。
一般に、あるデータに対する操作(オブジェクト指向においてはメソッドという形になる)が成功するためには一定の事前条件を満たしている必要があります。中には例えば「int型の値を2で割る」といった、ハードウェアが故障でもしていなければ絶対に失敗しようがない操作もある訳ですが、多くの場合は何らかの制約があります。例えば、内部にポインタを持っていて、それが有効なオブジェクトを指していない場合(ヌルポインタやダングリングポインタ、未初期化ポインタなど)はうまくいかない、といったケースです。
メソッドの実装はポインタが有効であることを前提に行われているのに、外側から内部ポインタを書き換えられてしまうのは都合が悪い。だから、メソッドの内部以外からは中身を見られたくない。これを解決するのがカプセル化です。オブジェクトの外側からアクセスしようとした時にエラーにしてしまえば良いというわけです。
C++の解決法:クラスメンバのアクセス指定子
C++はC言語と互換性があるように設計された言語のため、Cの構造体(struct)を取り込みました。一方でオブジェクト指向の概念を実装するため、クラス(class)という機能も追加しました。この2つの機能ですが、構造体もクラスもデータの組である点は同じで、さらにデータを操作するメソッドの機能をクラスだけではなく構造体の方にも追加したため、構造体とクラスはC++の言語機能としてはほぼ同一のものになっています。唯一の違いが、デフォルトのアクセス指定です1。以下、C++の文脈で「クラス」と言ったときは「クラスまたは構造体」のことを指すと思ってください。
C++はアクセス指定子として、 private, public, protected の3つを用意しました。 private はクラス内からしかアクセスできず、 public はクラス内外からアクセスでき、 protected はクラス内と、クラスを継承したクラス内からアクセスできます。
protected に関しては批判が多いのですが、これは継承に関する部分で扱います。継承について考えなければ public と private だけを使えば良いのですが、C++において public と private だけで十分な可視性の制御ができるかと言うと、実はそうではありません。クラスのメソッド以外の関数(C++ではフリー関数と呼びます)からもデータを直接扱いたいというケースがあるからです。
もちろん、オブジェクト X 型のオブジェクト x について f(x) という関数を実装したいのであれば、メンバ関数として X::f を定義する方が良いでしょう。ですが、2項関係などを考えるとそれだけではどうしようもありません。
X 型の値 x と Y 型の値 y について f(x, y) を定義したい場合、 x.f(y) としても y.f(x) としても、どちらかのメンバーでありどちらかのメンバーではないメソッドにしかすることができず、そうするとどちらかの private なデータにはアクセスできないことになります。
これでは都合が悪いので、C++では friend という機能を用意して、クラス外の指定した関数やクラスの中からは特別に private なメンバーにアクセスできるようにしています。
Rustの解決法:モジュール単位での可視性の制御
Rustにはクラス単位でのアクセス指定子はありません2。
その代わりに用意されているのが、モジュール単位での可視性の制御です。
そもそもなぜカプセル化が必要とされたのか、に立ち返ると、例えばクラスの開発者がそのクラスを使う開発者に不用意にいじってほしくない部分を隠す、などと言ったケースがあります。一方で、なぜ friend が必要となるかと言うと、クラスの開発者が二項関係などを定義したい時に中身が見えるようにする必要があるからです。
つまり、可視性の制御が必要なのは、クラスの中と外ではなく、クラスとその周辺機能を開発する開発者と、それを利用する開発者の間なのです。ライブラリ開発者とライブラリを利用する開発者では役割が異なります。開発時に異なるレイヤーの中身まで気にする必要がないようにするために情報の隠蔽は重要ですが、その境界線はクラスではないのです。
C++であれば namespace にその機能があればよかったのかもしれませんが、残念ながらそうはなりませんでした。
Rustにおいては、モジュールが関心の分離にちょうどいいレイヤーであることから、その内外で可視性を切り替える機能が提供されています。
pub struct Vec2D {
pub x: f64,
pub y: f64,
}
ありがちな2次元ベクトルを表すこんな構造を考えてみます。Rustでは pub キーワードをモジュール内のアイテムとstructのメンバーに対して使うことで可視性を変えられます。pub キーワードが付かない場合はデフォルトで最も不可視な状態になるので、 private に該当するキーワードはありません。
pub x: f64,
という風にメンバーごとに pub キーワードをつけていますが、これは構造体内外の可視性を表している訳ではありません。なんなら、
struct Vec2D {
x: f64,
y: f64,
}
としても、同一モジュール内であれば中身を直接扱うことができます。
struct Vec2D {
x: f64,
y: f64,
}
fn dot(a: Vec2D, b: Vec2D) -> f64 {
a.x * b.x + a.y * b.y
}
例えばこんな風に。
pub キーワードを使う場合、対象のアイテムやメンバーはどこからでも見える状態になります。一方、デフォルトの可視性ではモジュール内部からしか見ることができません。逆に言えば、モジュール内部であれば常に可視です。
Rustは多くの機能において、C++より制約が多い設計になっています。例えば変数のデフォルトは不変で mut を付けることで可変になる、ボローチェッカーがあり可変借用と不変借用を同時に作ることができない、などがその一面です。しかし、可視性の制御に関して、モジュール内に限れば常に可視であるのは、C++のクラスよりむしろ緩い制約であると言えます。
Rustのモジュールシステムはファイルシステムに合わせた構造になっているので、1つのモジュールはおおむね1つのファイルです。C++もそうですが、一般には複数のソースファイルの集まりとしてライブラリが作られ、それはRustでも同様です。Rustではライブラリはクレートという単位で配布され、ライブラリクレートはモジュールの木構造になっています。
デフォルトの可視性だと、上位のモジュールから下位のモジュール内のアイテムやメンバーを見ることはできません(逆は可能です。下位のモジュールは上位のモジュールの内部にあるためです)。しかし、 pub を付けるとライブラリクレートの内部だけでなく更に外側のクレートを利用する開発者にも見えるようになってしまいます。
つまり pub を付けるとライブラリの公開するインターフェイスであるということになるのですが、それだけでは都合が悪いため、Rustではさらに細かい可視性の制御ができるようになっています。 pub(crate) と書くとクレート内部では可視で、クレート外部からは不可視のアイテムやメンバーを定義できます。また、 pub(super) と書くと親モジュールから可視にすることができます。
ちなみに、 in キーワードを使うとさらに細かい制御ができます。例えば、 pub(in crate::a) と書くとクレートのルートモジュールの下にある a モジュールから可視になりますし、 pub(in super::super) と書くと親モジュールの親モジュールから可視になります。 pub(crate) は pub(in crate) と、 pub(super) は pub(in super) と同じ意味ですが、頻出なので特別にショートハンドが用意されていると考えれば良いと思います。実際、 in まで使う必要性はあまり生じません。
もうひとつ、モジュールによる可視性の制御は、C++のアクセス制御子を代替する機能であるのと同時に、 extern や static のようなリンケージを制御する仕組みでもあります。C++において、グローバルな、しかし外部から隠したい変数や関数を定義する時、翻訳単位を分けてその中で static や無名名前空間を利用して定義を行い、内部リンケージのシンボルとするのが一般的な方法ですが、Rustにおいては pub 付きのアイテムは外部リンケージに相当し、 pub の付かない(pub(crate)なども含む)アイテムは全て内部リンケージに相当します。 #[crate_type = "dylib"] などとして共有ライブラリを作成した場合、シンボルテーブルには pub を付けた物だけが残るということになります。
継承を分解する
継承とは?
継承こそがおそらくオブジェクト指向を巡る論争の主要な原因であろう、と思っています。
継承のそもそもの発想はシンプルです。「コードを再利用したい」これに尽きます。後述するポリモーフィズムもその発想の原点は同じでしょう。「DRY原則」というやつです。
- あるクラスAを作った
- そのクラスと同じような、しかし新しい機能を追加したクラスBが必要になった
- 同じようなクラスを2つ作るのはDRY原則に反している
- そうだ! クラスAの機能を引き継いでクラスBを作れるようにしよう!
確かに一見頷ける話ではあります。しかし、こうして生まれた継承には様々な問題がありました。例えば、
- 継承元の機能に変更が入った場合、継承先が自動でその変更を取り込んでしまう
- 継承先が状態に制限を加えたい場合でも、継承元の可変な参照にキャストできてしまうと不正な状態になりうる
- 多重継承を可能にすると、継承元の継承元に同じクラスがあった場合、どのように継承を行うかが問題になる(ダイヤモンド継承問題)
- 継承先が継承元の同シグネチャのメソッドを定義した場合、継承先から呼んだときと継承元にキャストして呼んだときで振る舞いが異なる
といった問題点が挙げられます。
C++の解決法:クラス継承
C++が用意したのは、継承の基本的なアイディアに対してナイーブな実装と言えるでしょう。
つまり、クラスBの一部を単純にクラスAにし、暗黙的なキャストを用意するという方法です。また、多重継承もナイーブに実装されています。つまり、クラスCがクラスAとクラスBを単純に同時継承するということです。
シンプルに実装された機能なのでシンプルに使えれば良かったのですが、実際はそうは行きません。特に、先述したように、多重継承を可能としたことでダイヤモンド継承問題が発生してしまいました。
ダイヤモンド継承問題
ダイヤモンド継承問題の解決策としてC++が用意したのは強引な方法です。仮想継承という手段を使って、継承先が継承元のメモリ上のオフセットを保持することで、2つ以上の継承先が1つのオブジェクトを継承元とすることができるようにしました。
ただ、この機能が有用かと言うと、個人的にはあまり有用とは思えません。実際の利用ケースも少ないでしょうし、後発言語で同じ機能が取り込まれているケースもおそらくほぼないと思われます。
仮想関数
同一シグネチャのメソッドの衝突に対する解決策としては、継承元のメソッドを呼んだ場合でも継承先メソッドが実行される、オーバーライドを可能とすることで解決が図られました。オーバーライドを可能とする関数を仮想関数と言い、仮想関数のメソッド呼び出しは、直接呼び出すのではなくオブジェクトが内部的に持つ仮想関数テーブルを経由して関数ポインタ相当の情報を利用して呼び出しを行うことになります。
仮想関数は、継承先が必ずオーバーライドを行うことにすれば継承元には必ずしも実装が必要ではないため、継承元で実装が不要な純粋仮想関数という機能も追加されました。
後述するポリモーフィズムにおいてこれは重要なアイディアであり、これを洗練させたのがJavaなどにおけるインターフェイスの概念なのですが、C++においてはインターフェイスとクラスの明確な区別はなく、「仮想関数を持たないクラス」「仮想関数を持つクラス」「純粋仮想関数を持つクラス」といった程度の区別がなされます。
しいて言えば、「(純粋)仮想関数を持ち、メンバ変数を持たないクラス」がインターフェイス相当なのですが、文法や言語機能上の区別はありません。
protected アクセス制御子
先程のカプセル化の部分で流した protected ですが、これは継承先から継承元のメンバーが見えるようにする仕組みです。
ですが、クラスの継承関係は実際のところ関心の分離のためのレイヤーとしてはあまり適切ではありません。例えばライブラリ開発者が作ったクラスをライブラリ利用者が継承することができます。 protected を使うということはつまり何らかの全公開したくない理由があるはずで、ライブラリ利用者が適切に使用してくれる保証はありません。
ライブラリ開発者が継承元と継承先を両方作るようなケースもあるとは思いますが、その場合であれば継承先のクラスを friend に指定したほうが安全です。
そういう訳で protected はあまり利用が推奨されない機能となってしまいました。
Javaの解決法:単一継承・インターフェイス実装
Javaにおいては、ダイヤモンド継承問題を避けるため、クラス継承は1つに限るという制約が存在します。
しかし、ポリモーフィズムのために、C++で複数の仮想関数を実装したクラスを継承するような仕組みは必要とされました。
そこで、クラスとは別にインターフェイスを用意し、 extends を使ったクラス継承とは別に implements を使ったインターフェイスの実装ができるようになっています。
Java(など)による整理によって、継承は2つの機能が実はキメラのように融合していたのだ、ということが明確になったと考えられます。
- クラス継承: データ構造を再利用する機能
- インターフェイス実装: 振る舞いを抽出したインターフェイスを実装し、インターフェイスのメソッドを呼び出す側のコードを再利用する機能
Rustの解決法:委譲・トレイト境界・トレイト継承
委譲
さて、ではRustではこの2つがどのように実装されているのか、ということなのですが、実はRustではクラス継承に相当する機能が実装されていません。
クラス継承の実際の構造を考えると、クラスBの一部がクラスAになっている、というものです。でもこれって、メンバー変数にAがあるのと同じじゃないですか?
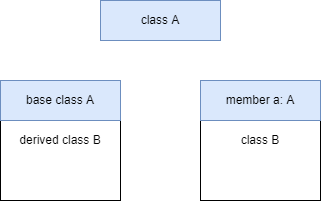
もちろん、メンバー変数に持つだけでは外部からメソッドを使える訳ではありません。そのため、BにAと同じメソッドを実装したければ、以下のようにする必要があります。
struct A {
}
impl A {
fn f() { todo!() }
}
struct B {
a: A,
}
impl B {
fn f() { a.f() }
}
このように、処理の一部を内部オブジェクトに委ねるような手法を委譲と言いますが、これを行うには委譲する処理全てに関してボイラープレートを追加する必要があります。
これを面倒だと考える人も多いようで(実際筆者もちょっと面倒です)、委譲を楽に書けるような提案が議論されたこともあるようですが、今のところ言語機能としては特に実装されていないようです。マクロを使ってボイラープレートを減らそうとするクレートなどは存在しています。
委譲のデメリットはいちいち引数を転送するだけのボイラープレートを書く必要があることですが、一方で特定の処理だけを委譲できるのはメリットでもあります。継承の場合、継承元の公開されたメソッドは問答無用で全て公開されてしまうため、場合によってはオブジェクトの状態が矛盾してしまうことになりかねませんが、委譲であれば公開したくない処理に関しては入口を作らないようにできます。
また、内部を全て公開しても差し支えないような場合は、単にメンバーを pub にすれば良いとも考えられます。
Rustにおいては、クラス継承の危険性と委譲の面倒さを検討して、安全側に倒したと言えるかと思います。
トレイト境界
さて、クラス継承の方は言語機能として取り込まなかったRustですが、一方でインターフェイスに相当する機能は存在します。それがトレイトです。
と言っても、後で詳述しますが、Rustのポリモーフィズムには静的なポリモーフィズムと動的なポリモーフィズムが存在し、トレイトはどちらの機能も背負っているため、C++の仮想関数が定義された抽象クラスのようなものとは違う機能を持ちます。JavaのインターフェイスはJavaにおけるジェネリクスの型パラメーター制約にも使用されるので近い部分もあるのですが、こちらもコンパイル時の型チェックが主なので異なる部分があります。
とは言え、基本的にはトレイトは機能を実装するために必要な処理を抽象化したもので、先発言語のインターフェイスと似たようなものです。トレイトを実装することはJavaにおけるインターフェイスのメソッドやC++における仮想関数をオーバーライドすることに相当し、トレイトを正しく実装すればコンパイルエラーがなくなり、必要な実装が欠けていればエラーになります。
Rustでは一つの型に対して複数の実装(内部でメソッドを定義できるブロック)を書くことができます。
ある型があるトレイトを実装する場合は、トレイトに対する実装を一つ追加する必要があります。これをトレイト境界と言います。
複数のトレイトに対応する場合は複数のトレイト境界を実装すれば良いのですが、別々のトレイトが同一シグネチャのメソッドを持っていた場合でも、トレイト境界ごとに分けることで実装対象のメソッドが一意に定まります。C++の仮想関数やJavaのインターフェイスでは同一シグネチャのメソッドのオーバーライドは、別々に抽象化されたものであっても同一の実装にせざるを得ないという問題があり、そこが解決されています3。
trait Trait1 {
fn f();
}
trait Trait2 {
fn f();
}
struct A;
// Aのトレイト境界ではない実装
impl A {
fn f() {} // 1
}
// Aに対するTrait1のトレイト境界の実装
impl Trait1 for A {
fn f() {} // 2
}
// Aに対するTraitのトレイト境界の実装
impl Trait2 for A {
fn f() {} // 3
}
// 1, 2, 3 はそれぞれ別の関数だが同時に定義できる
// トレイト境界でない実装は複数作れる
impl A {
}
// トレイト境界は一つに限られるので以下をコメント解除するとコンパイルエラー
// impl Trait1 for A
// {
// fn f() {}
// }
トレイト継承
クラス継承を廃したRustですが、継承という概念が全てなくなったわけではありません。
継承は型理論におけるSupertypeとSubtypeの関係を表しますが、この関係の抽象化は重要なものです。
そのため、Rustではトレイトの間では継承を行うことを可能としています。例えば、標準ライブラリの Eq トレイトは PartialEq<Self> トレイトを継承しており、 Eq トレイト境界を実装するには PartialEq<Self> トレイト境界も実装する必要があります。逆に言えば、 Eq トレイト境界が実装されている型には PartialEq<Self> トレイト境界も確実に実装されていると言える訳です。
トレイト継承は、あくまでトレイト同士の型レベルでの関係性を記述するためのもので、実装が引き継がれる訳ではありません。各トレイトに対するトレイト境界は個別に実装する必要があります4。
ポリモーフィズムを分解する
ポリモーフィズムとは?
ポリモーフィズム、多相や多態などと訳されますが、異なる場所で定義されたオブジェクトでも同一の振る舞いを実装し、呼び出し側からは同じように扱うことでコードの保守性や再利用性を高める機能です。
RubyやJavaScriptなど動的なスクリプト言語では動的なポリモーフィズムだけが存在しますが、C++やRustなどのコンパイル言語はコンパイル時にそれぞれの型に対するコード生成を行う静的なポリモーフィズムが可能です。もちろん動的なポリモーフィズムも存在するため、その2つを分けて話したいと思います。
C++の解決法:仮想関数・テンプレート・コンセプト・オーバーロード
仮想関数
仮想関数は継承の部分でも多く語りましたが、ポリモーフィズムのための機能と捉えることも可能です。仮想関数の実装があれば、異なる型でも同じように扱えます。また、純粋仮想関数を実装した基底クラスを継承することで、実装が必要な振る舞いを強制させることができます。
テンプレート
仮想関数と継承を利用したポリモーフィズムは動的なポリモーフィズムと言えます。一方で、静的なポリモーフィズムのために、C++にはテンプレートという機能が用意されています。
テンプレートを利用すれば、仮想関数のように仮想関数テーブルを経由することなく、異なる型のオブジェクトに対して同じ処理を適用するコードを生成できます。
コンセプト
ポリモーフィズムを語る時に「ダックタイピング」という言葉が持ち出されることがあります。「アヒルのように歩き、アヒルのように鳴くのなら、それはアヒルである」という意味らしいです。では、「アヒルのように歩き、アヒルのように鳴く」かどうかはどのように調べるのでしょうか?
動的なスクリプト言語では、オブジェクトが呼び出したいメソッドを持っていることを単純に期待してチェックを行わずによびだすか(その結果アヒルじゃなかった時にはエラーになります)、呼び出したいメソッドを持っているかを直前にチェックするか、といった手法が考えられます。
C++の場合、仮想関数を使った動的なポリモーフィズムでは、基底クラスを継承していればその振る舞いが実装されていることは確実です(純粋仮想関数の場合、実装がなければインスタンス化の際にコンパイルエラーになります)。
一方で、テンプレートには振る舞いを事前にチェックする機能がありません。そこで、テンプレートの実体化が行われる時に、個別の型について置き換えを試みて、必要なメソッドがなかったらコンパイルエラーになる、といった仕組みになっています。そしてこれがC++の数百行にわたるコンパイルエラー地獄の原因となっています。
今更そこは変えられないのですが、テンプレートの実体化の時に特定の振る舞いをする型かどうかの制約を加えたいという要求はずっとあって、以前はSFINAEという黒魔術でそれを行ってきたのですが、最近になってコンセプトという機能が導入されました。コンセプトは振る舞いを記述してひとまとめに扱うことができる機能で、Rustのトレイトにも若干近いと言えなくもないかな、くらいの機能です。
Rustのトレイト境界のようにコンセプトに記述された振る舞いを明示的に実装する方法はないのですが、型がコンセプトに記述された振る舞いを満たしているかどうかを static_assert でチェックするなどは可能です。あとは自力で実装してください、という話になりますが。
オーバーロード
もう一つ、オーバーロードもポリモーフィズムの一つです。ポリモーフィズムにはパラメトリック多相とアドホック多相の2種類があり、テンプレートは前者を、オーバーロードは後者を指します。もっとも、テンプレート関数のオーバーロードなどもできるため実際には両者入り混じった形になりますが。
アドホック多相は、具体的な型に対して必要な分の実装を個別に追加することを指します。これは対応する型が多くなったり予想がつかなくなると対応しきれなくなるため、そのような場合はテンプレートが使われます。
Rustの解決法:ジェネリクス・トレイトオブジェクト
ジェネリクス
C++のテンプレートに相当する機能は、Rustではジェネリクスと呼ばれます。テンプレートと同じくコンパイル時にコード生成を行う機能で、文法もテンプレートと似通った部分があるのですが、一つ大きな違いがあります。
C++のテンプレートでは、テンプレートの実体化が行われるまで型エラーのチェックがなされないため、文法エラーにならない限り型引数に依存する式であればどのような内容も書くことができます。
Rustのジェネリクスは、あらかじめ型引数にトレイト制約を書く必要があり、型引数が満たしているトレイトに実装された振る舞いしか書くことができません。これは、具体的な型を渡さなくてもコンパイル時にチェックされます。
以下のC++のコードはコンパイルに通りますが、
template<typename T>
auto size(T const& t) -> std::size_t {
return t.size();
}
以下のRustのコードはコンパイルエラーです。
fn len<T>(t: &T) -> usize {
t.len()
}
このようなケースなら通ります。
trait Len {
fn len(&self) -> usize;
}
fn len<T: Len>(t: &T) -> usize {
t.len()
}
トレイト制約は、型引数に依存する振る舞いを明示すると同時に、型引数に一致しない呼び出しをチェックしてエラーにする仕組みでもあります。関数内部での振る舞いがトレイト制約に記述されたものかのチェックと、関数呼び出しの側の型がトレイト境界を実装されたものかのチェックは個別に行われるため、型エラーが発生するコードを書いた場合でも、具体的なエラー位置の特定は容易で、何百行ものエラーが出てくるようなことにはなりません。
また、オーバーロードが複数存在するとオーバーロードそれぞれに対してチェックを行った結果を出力するのでエラーメッセージ増加の原因となりますが、Rustにはオーバーロードは存在しません5。そのため、エラーが発生した時もエラーが発生した位置1つが報告されます。
トレイトオブジェクト
C++の仮想関数、Javaのインターフェイスはいずれも動的なポリモーフィズムのために用意された機能であるため、内部的には仮想関数テーブルが用意され、関数ポインタ経由でメソッドが呼び出されることになります。
一方、トレイト境界が実装された型のオブジェクトに対してトレイトで抽象化されたメソッドの呼び出しは、それ自体は単なるメソッド呼び出しと同じように扱われ、仮想関数テーブルを経由することはありません。
ただし、トレイトが条件を満たす場合、仮想関数テーブルを作って動的ディスパッチを行うことも可能です。トレイト境界が実装された型の参照をサイズ不明のトレイトオブジェクトの参照にキャストして扱う方法で、内部的にはトレイトオブジェクトの参照はオブジェクトのポインタと仮想関数テーブルのアドレスのペアによるfatポインタ(ポインタ2個分の大きさがあるデータ構造)で実装されます。
トレイトオブジェクトは dyn キーワードを使って表されます。たとえば、トレイト X に対するトレイトオブジェクトは dyn X です6。
C++やJavaにおいては、仮想関数テーブルはオブジェクトの内部に保持され、その分だけオブジェクトが大きくなるのですが、Rustのトレイトオブジェクトでは、参照を作る時に元々のオブジェクトの参照と仮想関数テーブルのアドレスを組み合わせるようになっていて(これは静的に解決できる)、仮想関数テーブル自体、トレイトオブジェクトとして扱う必要がある場合にしか生成されない仕組みです。
C++の場合、動的なポリモーフィズムには仮想関数を、静的なポリモーフィズムにはテンプレートを使い、この2つの機能は乖離したものになっています。Javaにおいてはインターフェイスが動的なポリモーフィズムに使われるのと同時に、ジェネリクスの型制約にも利用できるため一貫性があるのですが、Javaのジェネリクスは最終的に型消去されて動的なポリモーフィズムになってしまうため、あくまでもコンパイル時の型チェックにしか使用できません。Rustはトレイトオブジェクトによって、静的なポリモーフィズムと動的なポリモーフィズムで一貫性のある型制約を記述できるようになっています。
まとめ
このように、Rustではオブジェクト指向の要素を分解して、必要に応じて実装を行っています。
| オブジェクト指向 | Rust |
|---|---|
| カプセル化 | モジュールやクレート単位での可視性の制御 |
| 継承 | クラス継承の廃止、必要な場合は委譲の利用、トレイト境界の実装、トレイト間の継承関係 |
| ポリモーフィズム | ジェネリクス(静的なポリモーフィズム)、トレイトオブジェクト(動的なポリモーフィズム) |
オブジェクト指向は決して万能の概念ではなく、欠点も多く含まれています。しかしまた、そこに含まれる要素にはいくつも重要なものがあり、すべてを否定することはできません。
そのため、Rustを通して見ることで、オブジェクト指向という概念を整理して、より高い解像度で理解できるのではないかと思います。同時に、「オブジェクト指向」というパッケージをそのまま取り入れるのではなく、そこに含まれる有用なものを抽出することの大事さも学べるのではないでしょうか。
Rust以外の言語を扱う時でも、Rustが行った取捨選択を考える意味はあるでしょう。言語機能として実装されていないため同じことができないケースもありますが、コードの安全性を高めるのに役に立つはずです。

- あと細かいことを言えば一部のABIでの扱い方が異なります(具体的にはMSVCの名前マングリングなど)。 ↩
-
そもそもRustにおけるデータ構造は
structかenumでありクラスはありませんがそれとは関係なく。 ↩ - ただし、同一メソッドの存在する二つ以上のトレイトを実装した型に対して呼び出しを行う時に曖昧になってしまう可能性はあります。それを解決する手段もありますが。 ↩
-
必要なトレイト境界を手動で全て実装するのは面倒なので、定型的に実装できるような型であればトレイトの作成者がトレイト境界を自動的に実装するための
deriveマクロを提供していることが多いです。 ↩ - オーバーロードのようなことがやりたくなったら、トレイトを作って個別の型に対してトレイト境界を実装し、ジェネリクスにトレイト制約を追加して、実際の処理をトレイト境界の実装に任せるようにすることができます。 ↩
-
歴史的には、型名が来る位置に表されたトレイト名はトレイトオブジェクトとして扱われる仕組みだったので、
Xのみでトレイトオブジェクトを表していました。しかしこれはトレイト制約に使う場合と非常に紛らわしいのでdynキーワードが導入され、Xのみでトレイトオブジェクトを表すのは警告が発生するようになっています。 ↩