こんにちは、hachi8833です。前回記事に続き、enno.jpにあえて搭載していない機能について書きました。
4. 設定のカスタマイズはサポートしない
enno.jpには、ユーザー向けの設定変更機能は付けていません。
前回記事で自動修正をサポートしなかったのと同じ理由で、ユーザーが設定について思いわずらう必要なしにチェックを進められることを優先することにしました。
他の機能については別のチェックツールとの併用をお願いします。私もそうしています。
5. 構文解析や機械学習は使っていない
enno.jpでは、構文解析や機械学習ベースのビッグデータ解析のような、意味に踏み込んだチェックは一切行っていません。外見だけで判断できるあからさまなエラーだけをチェックしています。
構文解析を取り入れていない理由は、手間がかかる割に精度が大して上がらず、効果が薄いと判断したためです。
ビッグデータなどを用いていない理由は、「制御が難しい」のと、「流し込んだテキストを一切保存しない」というポリシーのためです。
論文形式やコードには対応
その代わり、約物(パンクチュエーション)については、通常の「。、」の他に、論文などでよく用いられる「.,」にも対応しています。
さらに、文中にプログラミング言語のコードが含まれていても問題が生じないよう工夫しています。
これによって、「日本語文章」または「日本語に英語が少々混じった文章」であれば、分野を問わずほぼどんなテキストでもチェックできるようになりました。
英語以外の文章や単語を含む場合は、さすがに多少誤検出が生じるかもしれません。また、フォーマルな文章を念頭に置いているので、会話文や古文的な言い回しに対しては若干誤検出が生じることもあります。ご了承ください。
6. 送りがなやカタカナ揺れはサポートしない
「漢字の送りがなの揺れ」や「カタカナ表記の揺れ」は、議論が分かれるもののひとつです。そんな議論に付き合うつもりはないので、enno.jpでは送りがなやカタカナ表記の差異をチェック対象に含めていません。
参考: 送りがな - Wikipedia
そもそも、日本には正書法↓というものがありません。正書法とは、要するに「この書き方だけが正しい」「それ以外は間違い」という公式なルールの集合です。ヨーロッパの言語では国が正書法を定めていることがよくありますが、日本では告示にとどまるのみで強制力はなく、現実には正書法を適用するとむしろ混乱を招く可能性の方が高そうです。
参考: 正書法 - Wikipedia
個人的には、日本語の正書法が欲しいとも思いませんが、あっては困るとも思っていません。正書法ができたらできたで対処するまでです。
同音異義語のチェックを追加した
以下のような同音異義語は、発音も同じで、使われ方も非常に似ているため、コンテキストをよほど絞り込まないと正規表現だけでは取り違えを正しく検出するのが困難です。
- 「補足」「捕捉」
- 「自信」「自身」
後にこれについて、あからさまなエラーとは別に注意勧告の意味でハイライト色を変えて表示する機能を追加しました。
enno.jpより
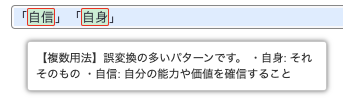
すべての同音異義語を登録するとうるさいだけなので、現実によく取り違えられる同音異義語だけを登録しています。
7. 禁止用語のチェックはサポートしない
6.にも関連しますが、いわゆる「放送禁止用語」「不適切用語」「差別用語」の検出はenno.jpではサポートしていません。理由は、こうした用語を検出する意義を自分が感じていないからです。
私は、「その気になればどんな言葉でも差別や攻撃に利用できてしまう」と考えています。enno.jpはコンテキストに依存しないエラーチェックを行っていますが、用語や言い回しが不適切かどうかはひたすらコンテキストによって決まると自分は考えているので、そうした用語のチェックはサポート外としています。
極端な場合、まったく同じ言葉であっても、それを誰が発したかによって意味が180度変わることすらあります(例: Stay hungry, Stay foolish)。これをテキストだけから機械的に検出するのは原理的に不可能です。
8. エラーパターンのメンテナンス機能は非公開とした
オープンソースの精神に則って、エラーのパターンをGitHubあたりに公開して、enno.jpのエラーパターンを大勢でメンテしたり、他のツールにインポートして利用したりという可能性についても一度検討しました。
そして検討の結果、エラーパターンは非公開とし、自分だけがメンテすることに決めました。
理由は、オープンな場でのエラーパターンのメンテナンスは自分にとってデメリットが大きいと判断したからです。
あからさまなエラーに限定するとはいえ、それでも必ず議論が割れると予想しました。そして「正しい」「間違ってる」は個人の好みや主観にまみれがちです。そうした議論を調停する資格が自分にあるとも思えませんし、議論に吸われる時間も膨大なものになりそうです。
大勢でメンテするとなれば、エラーパターンの修正方法に関するスタイルガイドも作らなければなりません。しかしメンバーが増えれば、それが徹底されない可能性の方が遥かに大きいと予想しました。
正規表現の修業の場
もうひとつ自分にとって重要なのは、enno.jpのエラーパターンのメンテナンスが、私の大好きな正規表現の一人修行の場になっていることです。
私はenno.jpにエラーパターンを登録するときは、常に以下を心がけています。
- エラー検出を極力一般化すること(でも無理はしない)
- 誤検出(false positive)を極力減らすこと
- 複数のエラーパターンによる検出が重複しないようにすること
- ハイライトの範囲を極力絞り込み、ユーザーの目に余分な負担をかけないようにすること
- ReDoS脆弱性を埋め込まないようにすること
おまけ: エラーパターンの見つけ方
ネットや本で見かけたあからさまなエラーや誤字脱字を登録することももちろんあります。しかし最も登録の頻度が多いのは「自分自身がやってしまったあからさまなエラーや誤字脱字」かもしれません。
私はこうしたミスが非常に多いので、同じミスを二度と繰り返さないためにenno.jpを作ったと言っても過言ではありません。
何らかの法則に基づいてランダムなエラーパターンを自動生成するという手もなくもないのでしょうが、おそらく効率はよくないと思います。
自分は、実際にはほとんど発生しないランダムなエラーパターンを生成するよりも「実際に起きたエラー」を登録する方が、有効なパターンを効果的に蓄積できる可能性が高まると考えました。
参考: 客の来店する時間間隔が指数分布になる直感的な理由と、分布の導出方法 - roombaの日記
こんなデータを有料で欲しい人は果たしてこの世にいるのでしょうか。もしそんな奇特な方がいらっしゃいましたら@hachi8833までお知らせください。個人的には、文部科学省に買っていただきたいところです。