主にRubyを中心としながらも、なるべく一般的な形で正規表現を解説しています。誤りやお気づきの点がありましたら@hachi8833までどうぞ🙇。
注意
本記事に記載されているReDoSを引き起こすテスト文字列の長さはregex101.comなどのサービスに影響を与えない長さにとどめてあります。
![]() これらのサービスで試すときに文字列のスペースを増やさないようお願いします。
これらのサービスで試すときに文字列のスペースを増やさないようお願いします。
![]() また、本記事で紹介したようなテスト文字列をWebサービスに入力・送信しないようお願いします。
また、本記事で紹介したようなテスト文字列をWebサービスに入力・送信しないようお願いします。
11: 最もシンプルなReDoSと回避方法
早速ですがクイズです。
🔗 問題1.
テキスト検査用に「テキストの行末にスペースが存在するかどうか」を検出する正規表現を手書きしてみてください。
テスト文字列の1つ目は連続スペース(マッチすべき)、2つ目は連続スペースの末尾にスペース以外の文字がある場合(マッチしてはならない)です。本記事では基本的にこれをテスト文字列として使います。必要な方はregex101.comからお取りください。
regex101.comより、以下同じ
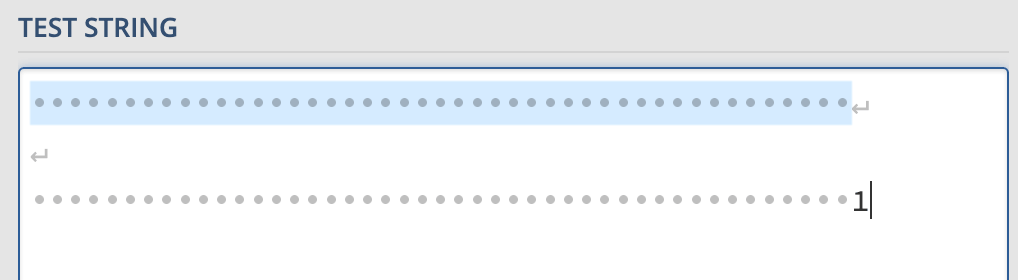
🔗 予想解答1.
末尾スペースの存在確認だけなら、以下のように書く人が多そうです。
[ ]$
これは単なる肩慣らしなので、次いきましょう。
補足
以下の記事にも書いたように、RubyやPHPの正規表現で^や$を使うのは原則として避けるべきです。
ただしここでは、文字列全体の末尾スペースではなく行末のスペースを検出したいので、$は容認しています。
🔗 問題2.
では今度は、テキストをハイライトするために「テキストの行末に残っているスペース全体」にマッチさせる正規表現を手で書いてみてください。
🔗 予想解答1
以下のように書いた人が多いのではないかと思います。[ ]にはスペースが入っています。
[ ]+$
しかしこれは、ReDoSになる危険なパターンです。これ以上シンプルなReDoSパターンを私は知りません。
見てのとおり、成功時は3ステップで完了しているのに、失敗時には完了までに1084ステップもかかっています。
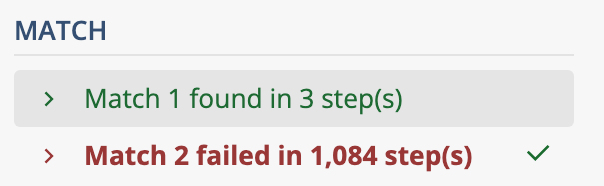
このステップ数は、途中のスペースを増やすとどんどん増えていきます。
🔗 危険な理由
この[ ]+$パターンを以下のrecheck Playgroundで検査してみてください。
recheckのPlaygroundでは、冒頭と末尾に/を追加する必要があります。
本記事で扱う正規表現の記法には、冒頭と末尾の/は追加しませんのでご了承ください。
Playground | recheckより、以下同じ
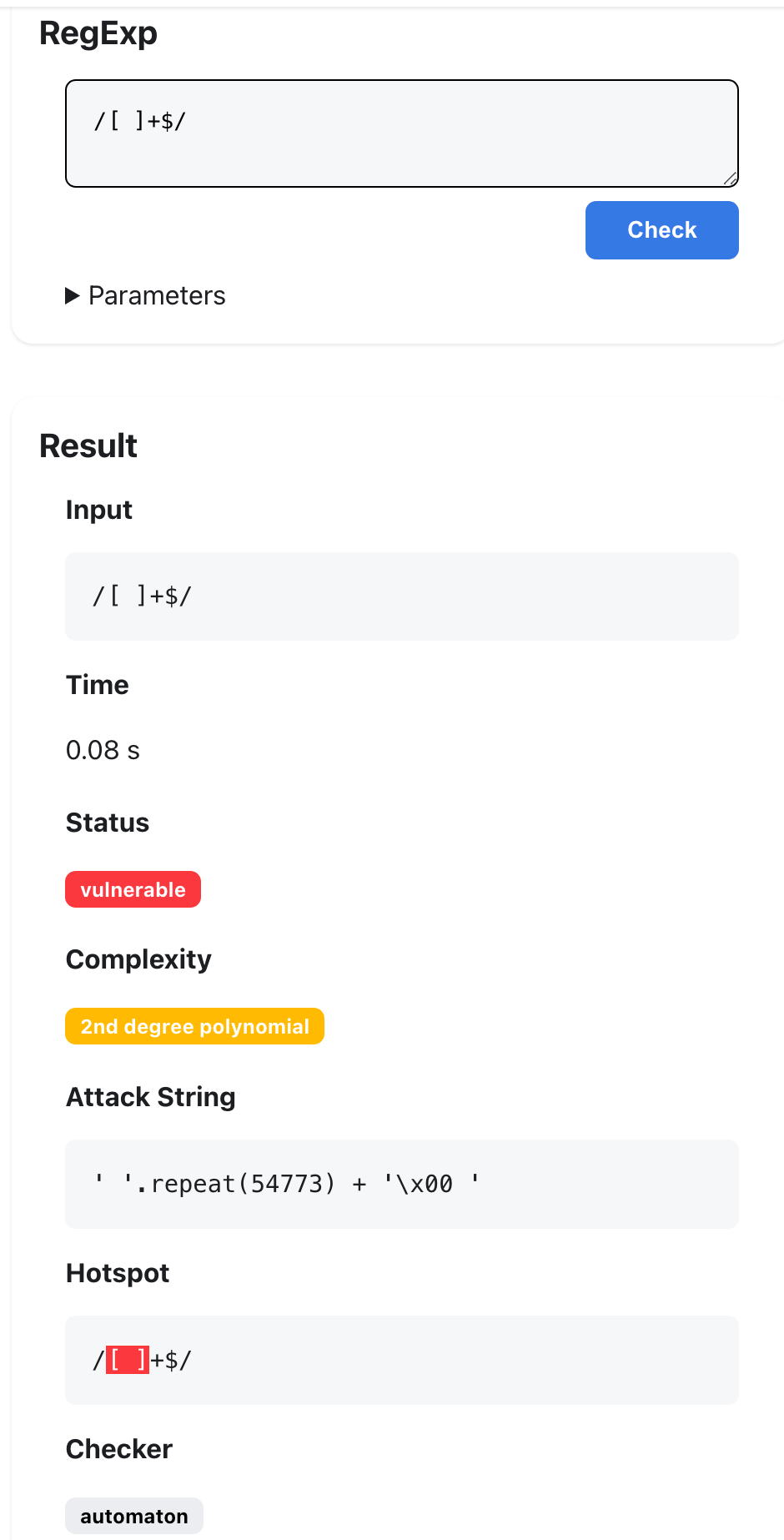
このrecheckは、アドホックな経験則を積み重ねて検査するのではなく、正規表現を「理論ベースで」解析してReDoSになりうるかどうかを判定するすぐれものです。

バックトラックを行う正規表現エンジンで、^のような先頭アンカーがない正規表現を使って部分一致検索を行うと、開始位置を1文字ずつずらしながら照合を試みます。そのため、末尾スペースを検出するつもりだった[ ]+$のようなパターンでは、スペースが100個なら残り99個、98個、97個…といった具合に同様の照合を繰り返すことになり、失敗時のステップ数が増えてしまいます。
この正規表現の複雑さは"2nd degree polynomial"(2次多項式的増加)と表示されているので、文字列の長さをnとすると複雑さは![]() で増加します。
で増加します。
参考までに、recheckのPlaygroundにサンプルで表示されている^(a|a)*$の複雑さは"exponential"(指数関数的増加)なので、複雑さは![]() で増加します。
で増加します。
[ ]+$の複雑さの増加は2次多項式的増加なので、^(a|a)*$の指数関数的増加よりはマシとはいえ、やはりReDoSにつながる危険なパターンと言えます。recheckがこれをvulnerable(脆弱)と判定しているのは納得です。
この失敗する文字列(多数のスペースの末尾に文字を置いたもの)をうんと長くしたテスト文字列は、末尾スペースを[ ]+$で検出しているWebサービスで簡単にReDoSを引き起こせます。繰り返しますが、悪用厳禁ですからね。
🔗 修正例1
まずは私が従来使っていた最小限の応急処置から。
以下はrecheckで「safe」になります。
(?<![ ])[ ]+$
RubyのOnigmoのステップ数はわかりませんが、regex101では失敗の場合に192ステップで済んでいます。
🔗 参考
なお、私がenno.jpで長年使っていた正規表現はこれをベースにしていて、以下のようなものでした。
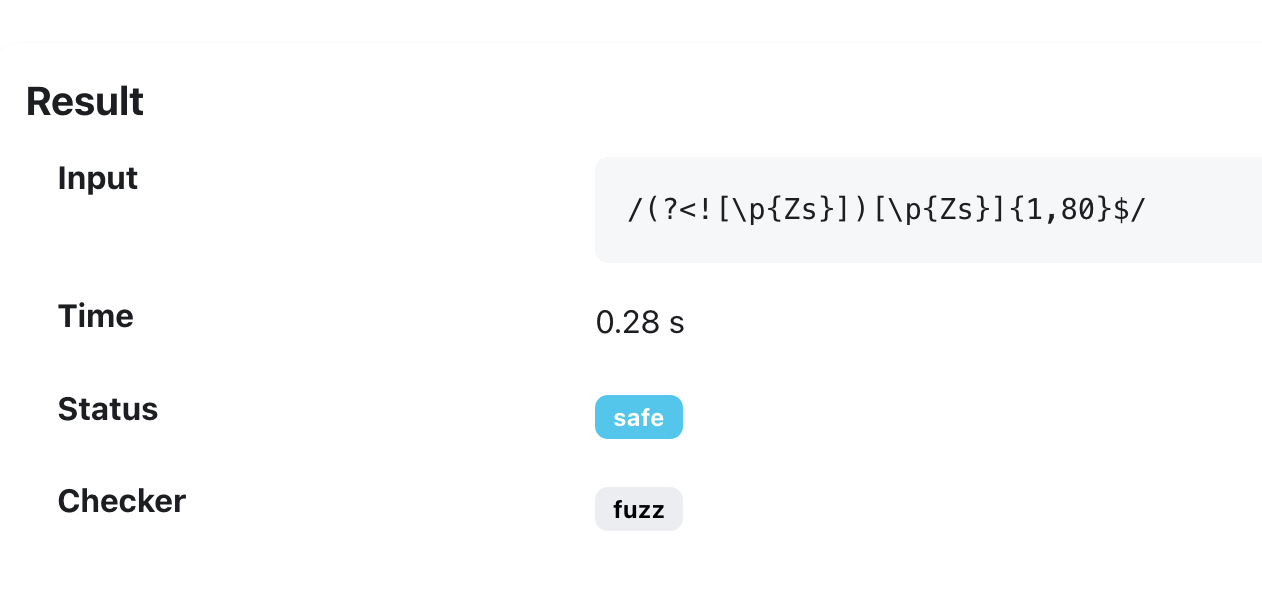
(?<![\p{Zs}])[\p{Zs}]{1,80}$
[ ]の代わりにZsという文字クラスを使っています
(nbspなどあらゆるスペース文字にマッチさせるため)(?<![\p{Zs}])という「後読みの否定」を置くことで、試行回数を大幅に削減しています
(しくみは異なりますが、後述の絶対最大量指定子とほぼ同等の効果)- オプション:
+や*ではなく、上限のある{1,25}を使うことでReDoSのリスクを軽減しています
(処理の足切り用なので、パフォーマンスは向上しません)
通常の文章で行末スペースが80文字を超えることはほとんどないだろうという経験則に基づいています
このパターンでは、少なくともReDoSは発生しません。
🔗 修正例2
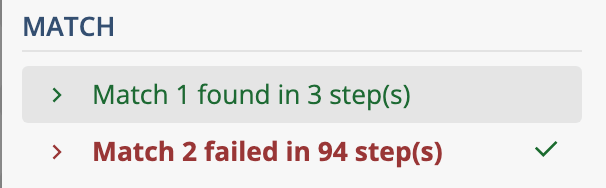
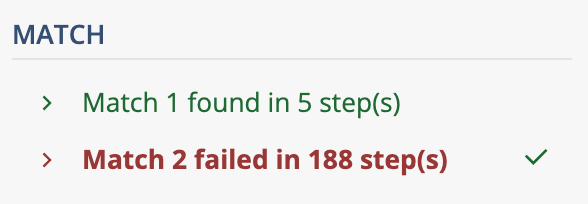
++などの絶対最大量指定子(possessive quantifier)や(?>)のアトミックグループ(atomic group)を知っている人なら、こう書くかもしれません。
[ ]++$ # 絶対最大量指定子
(?>[ ]+)$ # アトミックグループ
regex101で調べると、絶対最大量指定子[ ]++$は94ステップ、アトミックグループは188ステップで収まりました。
バックトラックが不要なパターンであれば、ナイーブな+や*よりも絶対最大量指定子かアトミックグループを検討しましょう。
ただし絶対最大量指定子やアトミックグループは正規表現エンジンによってサポートに差があります。
あの最強の.NETの正規表現ライブラリは絶対最大量指定子をサポートしていません(といっても両者は本質的に同じなので、アトミックグループで代用できます)。
惜しいことに、recheckはこれらの記法に対応していないためunknownと判定されます。


🔗 修正例3:「正規表現を使わずに」末尾スペースとマッチさせる
これが最もおすすめです。
マッチに正規表現を使わない方法に切り替えることで、ReDoSを解決するだけでなく、パフォーマンスも大幅に向上します。
▶コードとベンチマーク(クリックで展開)
SpaceMatcherNoRegexが正規表現を使わない方法です。
比較対象となるSpaceMatcherRegexの正規表現は、今回最も高速だった絶対最大量指定子による[ ]++$を使いました。
# Copilot経由でGemini 3 Previewを用いて生成
require 'benchmark'
# Match result type
Match = Data.define(:begin_pos, :end_pos)
class SpaceMatcherRegex
# Possessive quantifier for trailing spaces
TRAIL_RE = /[ ]++$/
def initialize(text)
@text = text
end
def match
results = []
offset = 0
@text.each_line do |line|
# Remove newlines manually to match the logic provided
s = line.delete_suffix("\n").delete_suffix("\r")
if (m = TRAIL_RE.match(s))
results << Match.new(
begin_pos: offset + m.begin(0),
end_pos: offset + m.end(0)
)
end
offset += line.length
end
results
end
end
class SpaceMatcherNoRegex
def initialize(text)
@text = text
end
def match
results = []
offset = 0
@text.each_line do |line|
# Calculate content length without trailing newline
len = line.length
content_len = len
if line.end_with?("\n")
content_len -= 1
if content_len > 0 && line[content_len - 1] == "\r"
content_len -= 1
end
end
# Scan backwards from the end of content
# We want to find a sequence of spaces at the end of the content.
# i points to the character we are checking.
i = content_len - 1
while i >= 0 && line[i] == ' '
i -= 1
end
# i is now the index of the last non-space character.
# The spaces start at i + 1.
start_index = i + 1
# Check if we found any spaces at the end
if start_index < content_len
results << Match.new(
begin_pos: offset + start_index,
end_pos: offset + content_len
)
end
offset += len
end
results
end
end
# Test string as requested
text = " " * 100_000 + "1"
puts "Benchmarking with text length: #{text.length}"
# Verify correctness (simple verification, though intended for benchmark)
r1 = SpaceMatcherRegex.new(text).match
r2 = SpaceMatcherNoRegex.new(text).match
# Since the test string ends in "1", there are no trailing spaces at the end of the line.
# Let's add a case aimed at matching trailing spaces too for verification.
text_match = "1" + " " * 100_000
r1_match = SpaceMatcherRegex.new(text_match).match
r2_match = SpaceMatcherNoRegex.new(text_match).match
if r1_match != r2_match
puts "WARNING: Results do not match!"
puts "Regex: #{r1_match.inspect}"
puts "No Regex: #{r2_match.inspect}"
end
Benchmark.bm(15) do |x|
x.report("Regex ([ ]++$):") do
100.times { SpaceMatcherRegex.new(text).match }
end
x.report("No Regex:") do
100.times { SpaceMatcherNoRegex.new(text).match }
end
end
私の手元の環境での実行結果からもわかるように、正規表現を使わずに末尾スペースにマッチさせる方が500倍以上高速です。
$ ruby benchmark/space_matcher_benchmark.rb
Benchmarking with text length: 100001
user system total real
Regex ([ ]++$): 0.417188 0.045713 0.462901 ( 0.463074)
No Regex: 0.000717 0.000109 0.000826 ( 0.000827)
以下の記事もどうぞ。
ついでながら、先ごろリニューアルしたenno.jpにもこのReDoSに強い末尾スペースチェックを導入しました。
🔗 まとめ
- 正規表現よりも専用メソッドやスクラッチのロジックの方がたいてい圧倒的に高速
- 正規表現を使う前にrecheckで必ずチェックしよう
+や*といったナイーブな量指定子をいきなり使うのは避け、可能なら{1,25}のように上限のある量指定子を使おう- 長さ不定の量指定子が必要なら、絶対最大量指定子(
++など)かアトミックグループ((?>))を使おう - ReDoSを引き起こすテスト文字列をWebサービスなどに送信してはいけません
|と部分マッチのワナ.*や.+がバックトラックで不利な理由