こんにちは、hachi8833です。怖いもの見たさでPerlの記事書いてみました。
Perlはどこから来るかしら
PerlのCGIを新規で開発することは昨今ほとんどなくなったかと思いますが、Git管理もされていない、世界遺産入り間近と思われるほどの年代物CGIがメンテナンス案件として突如舞い降りてくることがごくごくたまにあるものです。

私のような者でもすぐに目につくのは次のような特徴です。
$がやたら多いmyという名の変数(レキシカルスコープ変数)がある(myを付けないとグローバル変数になってしまいます)- PCREという強力な正規表現ライブラリの本家
しかしこの程度でperlに立ち向かうことができるのでしょうか。ググッて調べようにも、知らないことはググりようがありません。他の言語と同様、perlにもきっと「ここを外したらマズイ!」という急所がきっとあるはずだと妖怪アンテナが知らせてくれています。
そこで、BPS社内のperl使いでもある豪腕インフラエンジニアのyamasitaさんに教えていただきました。

その1: use warnings;とuse strict;
何はなくとも「コードの先頭で必ず以下を指定すること」だそうです。
use warnings;
use strict;
『Perlプログラミング救命病棟』という書籍の5ページにこんなことが書かれています。
Perlプログラムでこれらの行を割愛するのは、CEOの会議室の椅子にブーブークッションを仕掛けるようなもので、プロフェッショナルとして自殺行為に近いことです。
Perlプログラミング救命病棟
あのときメンテしたperlのコードにはたぶんなかった...
その2: encodeとdecode
もうひとつは、Perl 日本語文字列の扱い encode /decode, flagged utf8, EUC-JP (0x244) にある次の文です。
入り口で decode して、内部ではすべて flagged utf8 で扱い、出口で encode する。これがすべてです! とにかくこの基本方針をまもっていれば幸せになれます。
Perl 日本語文字列の扱い
詳しくはリンク先に譲りますが、あれこれググる前にここを押さえておかなければ、果てしなく遠回りすることになりそうです。
yamasitaさんが図まで書いてくれました。
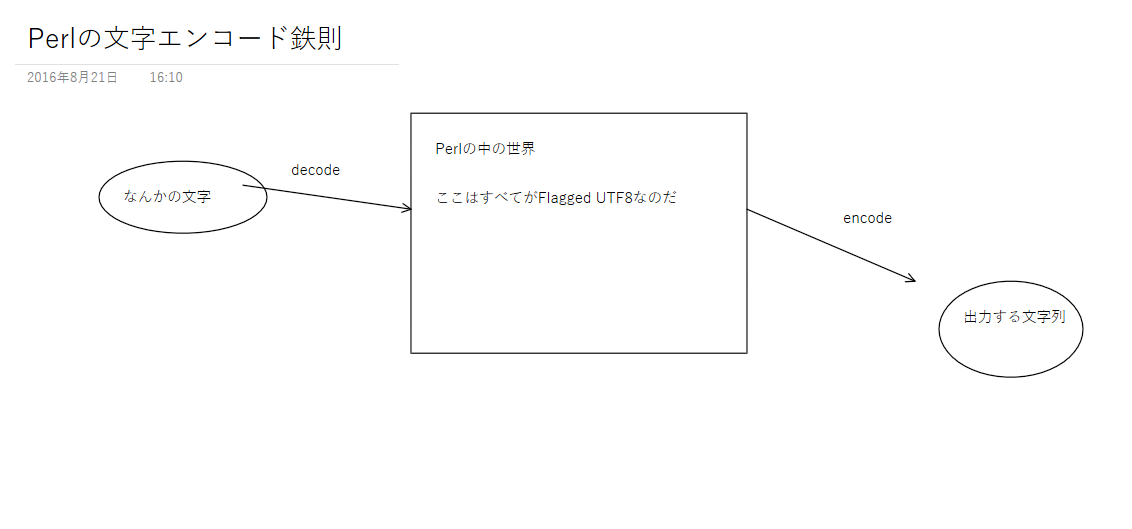
perl世界に何らかの文字を読み込むときには、decodeで文字をflagged utf8に変換し、出力の際にencodeで元のエンコードに戻すのが確実です。
内部エンコーディングはflagged utf8にしておかないと、正規表現をはじめとする多くの関数が期待どおりに動かなくなる可能性があります。さらにflagged utf8はUTF8と同じではありません。元がUTF8の場合にencodeとdecodeを省略するとワーニングが表示されることがあります。
以下は同じくPerl 日本語文字列の扱いからの抜粋ですが、ざっくりこんな流れになるようです。リンク先ではこの他にもエンコード周りの注意点が記載されていますのでじっくりお読みください。
my $dec_string = decode('utf-8', $string);
my $dec_substr = decode('utf-8', $substr);
my $where = index($dec_string, $dec_substr);
my $enc_substr = encode('utf-8', $dec_substr);
追伸
perlにはさまざまな手法を許容する文化があるので、「こうしなければ」とは型にはめることはあまりしないようです。yamasitaさんによると、中にはuse bytes;を指定してすべてバイト列として扱うツワモノもいるんだそうです。
メモ: Rubyのエンコーディング
Rubyでは、バージョン2.0でスクリプトファイルのエンコーディングがデフォルトでUTF-8として扱われるようになりました。
2.0より前のRubyでは、スクリプトファイルの冒頭にマジックコメント(下)を書いたり、スクリプトファイルのエンコーディングを-Kオプションで指定したり、iconvライブラリで文字コードを変換したりしていました。
# coding: utf-8
- 1.8.7以前: デフォルトはUS-ASCII、日本語を扱う際は$KCODEの指定を明示的に呼び出す
- 1.9.3以前: デフォルトはUS-ASCII、日本語を扱う際は
coding: utf-8等のマジックコメントを記述する - 2.0.0以降: デフォルトはUTF-8
このあたりのことは、morimorihogeさんのTechRacho記事「RubyでShiftJISのファイルを扱う(1.9.3, 2.0系対応版)」に詳しく書かれています。
なお、エンコーディング指定の優先順位は以下のとおりになります。
- magic comment(最優先)
- -K オプション
- RUBYOPTの-Kオプション
- ファイルのshebang(例:
#!/usr/bin/env ruby -Ku)
Ruby 2.0.0がサポート終了した今となっては昔話ですが、レガシーシステムで非UTF-8エンコードのファイルが使われている場合は必要になる可能性があります。
Ruby 2.0以降で文字コードの問題をまったく考えずに済むようになったということではありませんが、UTF-8ベースでの処理が中心になったことでエンコードの扱いは楽になりました。