@gfxさん作のruby-regexp_trie gemを使うと、Rubyで文字列の配列から凝縮された正規表現を楽に生成できることを知りました😍。
文字列リストを単に|でつなげるだけならRuby標準のRegexp.unionでもできますが、文字列リストが巨大になってくると単純連結では効率が低下します。
以下説明のために、わざとソート順を崩したaryを用います。
ary = %w(
YMS-15
MSM-10
YMS-14
MAN-07
MSN-02
MSM-07S
MA-05
MSM-07
MSM-04F
MSM-03
MS-X16
MAN-03
MS-X10
MS-14A
MS-R09
MS-06F
MS-14
MS-11
MS-09R
MS-09
MS-07B
MS-07
MS-06S
MS-06J
MS-06
MSN-X2
MS-05B
MAX-03
MS-14S
MAN-X3
MAN-08
MA-08
MA-05H
MAN-X8
MA-04X
MSM-04
MAM-07
YMS-07B
)
» p Regexp.union(ary)
#» /YMS\-15|MSM\-10|YMS\-14|MAN\-07|MSN\-02|MSM\-07S|MA\-05|MSM\-07|MSM\-04F|MSM\-03|MS\-X16|MAN\-03|MS\-X10|MS\-14A|MS\-R09|MS\-06F|MS\-14|MS\-11|MS\-09R|MS\-09|MS\-07B|MS\-07|MS\-06S|MS\-06J|MS\-06|MSN\-X2|MS\-05B|MAX\-03|MS\-14S|MAN\-X3|MAN\-08|MA\-08|MA\-05H|MAN\-X8|MA\-04X|MSM\-04|MAM\-07|YMS\-07B/
ご覧のとおり、Regexp.unionはそのまんま|で結合されます。
参考: singleton method Regexp.union (Ruby 2.6.0)
使い方
READMEに書かれています。
以下を実行してgemをインストールします。
$ gem install regexp_trie
pryで動かしてみます。
» require 'regexp_trie'
# 上のaryをここに貼ってから以下を実行(以下略)
» re = RegexpTrie.union(ary)
#» /(?:YMS\-(?:1[54]|07B)|M(?:S(?:M\-(?:10|0(?:7S?|4F?|3))|N\-(?:02|X2)|\-(?:X1[60]|1(?:4[AS]?|1)|R09|0(?:6[FSJ]?|9R?|7B?|5B)))|A(?:N\-(?:0[738]|X[38])|\-0(?:5H?|4X|8)|X\-03|M\-07)))/
» re.match?("MA-09")
#» false
» re.match?("MAN-X3")
#» true
文字列リストが見事に正規表現として凝縮されました。リストにない文字にマッチすることもありません。丸かっこは(?:でちゃんとキャプチャを抑制してくれていますのでパフォーマンス上も有利ですね😋。
正規表現オプションの指定方法
option: Regexp::IGNORECASEのようにキーワード引数で正規表現オプションを指定できます。
» re = RegexpTrie.union(ary, option: Regexp::IGNORECASE)
#» /(?:YMS\-(?:1[54]|07B)|M(?:S(?:M\-(?:10|0(?:7S?|4F?|3))|N\-(?:02|X2)|\-(?:X1[60]|1(?:4[AS]?|1)|R09|0(?:6[FSJ]?|9R?|7B?|5B)))|A(?:N\-(?:0[738]|X[38])|\-0(?:5H?|4X|8)|X\-03|M\-07)))/i
» re.match?("man-03")
#» true
よく使いそうなのは以下です。
Regexp::IGNORECASE: 大文字小文字を区別しない(/iに相当)Regexp::MULTILINE:.が改行にマッチするようになる(/mに相当)
参考: 定数 -- class Regexp (Ruby 2.6.0)
制約
RegexpTrie.unionは文字列リテラルのみを対象としますRegexpTrie.unionに空文字列を渡すことはできません
生成された正規表現をチェック
生成された正規表現に適当に改行を入れて、少し詳しく見ていきます。
(?:
YMS
\-(?:1[54]|07B)|
M(?:
S(?:
M\-(?:
10|
0(?:
7S?|4F?|3))|
N\-(?:
02|X2)|
\-(?:
X1[60]|
1(?:
4[AS]?|1)|
R09|
0(?:
6[FSJ]?|
9R?|
7B?|
5B)))|
A(?:
N\-(?:
0[738]|
X[38])|
\-0(?:
5H?|
4X|
8)|
X\-03|
M\-07))
)
aryのソートをわざと乱していましたが、生成された正規表現は、最も長いモデル名であるYMSやMSMやMSNやMANやMAXが最初にチェックされており、「|の列挙は長いものから順に」の原則にも沿っています😍。
文字列はソートしなくてよい?
ruby-regexp_trieで処理する前に、不揃いの文字列リストをsort.reverseしてみたところ、生成される正規表現は少し違いがでました。どれも挙動は変わらないので、|の前後の交換可能な部分が入れ替わっているだけのようです。
» re = RegexpTrie.union(ary)
#» /(?:YMS\-(?:1[54]|07B)|M(?:S(?:M\-(?:10|0(?:7S?|4F?|3))|N\-(?:02|X2)|\-(?:X1[60]|1(?:4[AS]?|1)|R09|0(?:6[FSJ]?|9R?|7B?|5B)))|A(?:N\-(?:0[738]|X[38])|\-0(?:5H?|4X|8)|X\-03|M\-07)))/
# 上と下で結果が微妙に違うが結果は変わらない
» re = RegexpTrie.union(ary.sort.reverse)
#» /(?:YMS\-(?:1[54]|07B)|M(?:S(?:N\-(?:X2|02)|M\-(?:10|0(?:7S?|4F?|3))|\-(?:X1[60]|R09|1(?:4[SA]?|1)|0(?:9R?|7B?|6[SJF]?|5B)))|A(?:X\-03|N\-(?:X[83]|0[873])|M\-07|\-0(?:5H?|4X|8))))/
» re = RegexpTrie.union(ary.sort)
#» /(?:M(?:A(?:\-0(?:4X|5H?|8)|M\-07|N\-(?:0[378]|X[38])|X\-03)|S(?:\-(?:0(?:5B|6[FJS]?|7B?|9R?)|1(?:4[AS]?|1)|R09|X1[06])|M\-(?:0(?:4F?|7S?|3)|10)|N\-(?:02|X2)))|YMS\-(?:07B|1[45]))/
READMEにも「ruby-regexp_trieは文字列の順序に依存しない」とあるので、わざわざsort.reverseとかする必要はなさそうです。
生成された正規表現の効率をチェック
最近私が愛用しているregex101.comで、単なる|結合とruby-regexp_trie生成の正規表現を比べてみました。
サンプルとしては、それぞれの正規表現の末尾に相当する文字列を最悪のケースとして使いました。
|結合の場合 -- 50ステップ
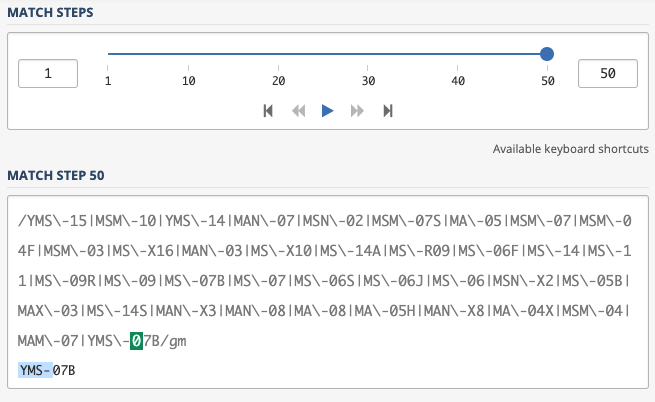
- ruby-regexp_trieで変換した場合 -- 18ステップ
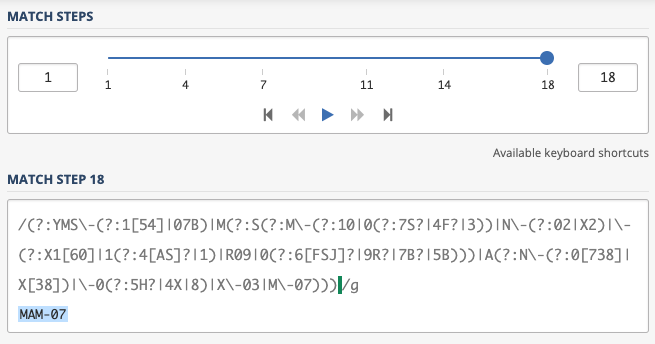
結果はruby-regexp_trieの圧勝です。左サイドバーの「Regex debugger」をクリックして動かせば実感が伴うと思います。
参考: 語の境界と部分マッチには注意
以下はruby-regexp_trieに限りません。ruby-regexp_trieを使おうと使うまいと、状況によっては誤った部分マッチを呼び込んでしまう可能性があります。
もちろん、部分マッチが誤検出かどうかは目的によりますので、部分マッチが即誤りとは限りません。
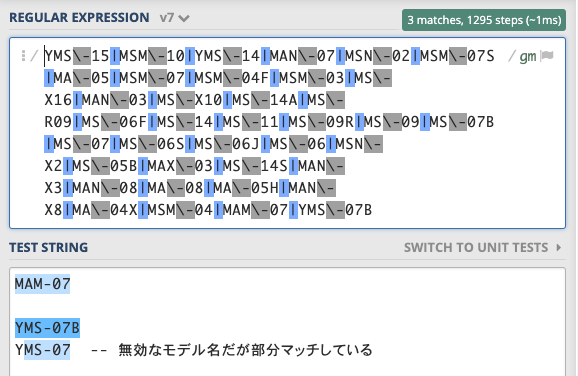
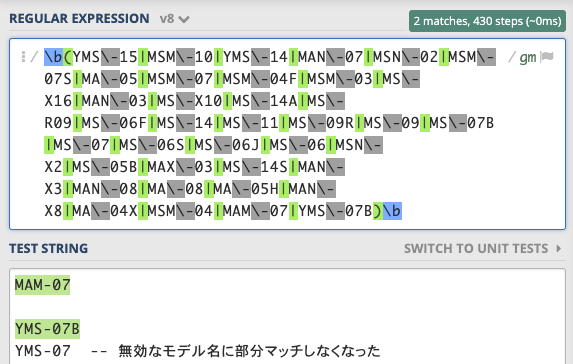
|結合の誤検出 --MS-07がYMS-07という無効な文字列にマッチしている
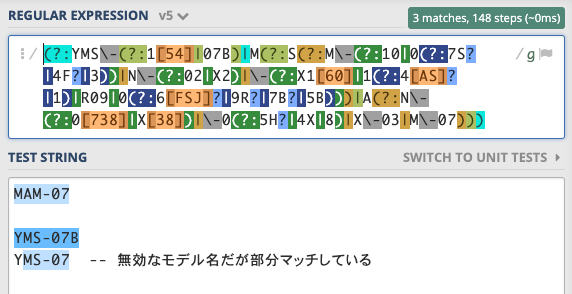
- ruby-regexp_trieの誤検出 --
MS-07がYMS-07という無効な文字列にマッチしている
回避方法
検索対象の文書が英語のようなスペース区切りの文字列であれば、\b(と)\bで正規表現全体を囲むことで部分マッチを回避できます。この場合ステップ数は若干増えます。
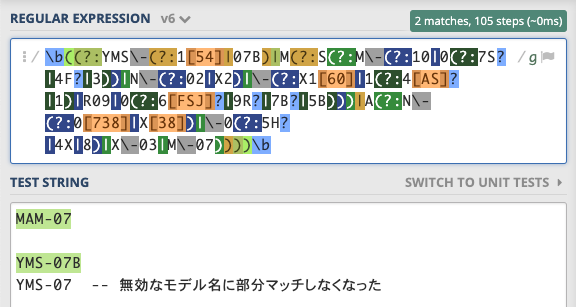
日本語では\b(と)\bが使えない
ただし正規表現を\b(と)\bで囲む方法は、日本語の文字列(正確には日本語や中国語のようなスペース区切りでない文書)では基本的に部分マッチを排除できません。試しに日本語の正規表現を\b(と)\bで囲むとほとんどマッチしなくなってしまいます。
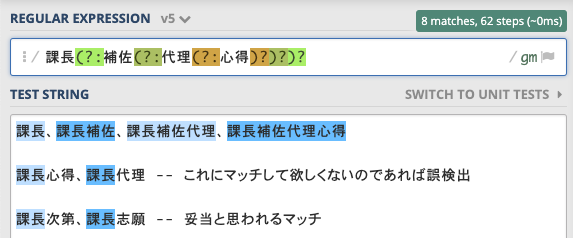
- 上に
\bを追加した場合 -- 本来のマッチまで消えてしまった😇
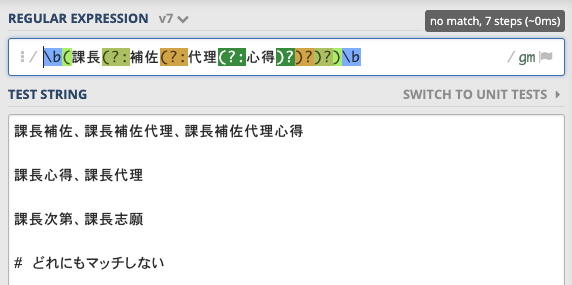
日本語の場合の回避方法
排除したい部分マッチがある場合は、たとえば以下のように正規表現を手動で追加する必要があります。スペース区切りでない言語の限界ですね😢。
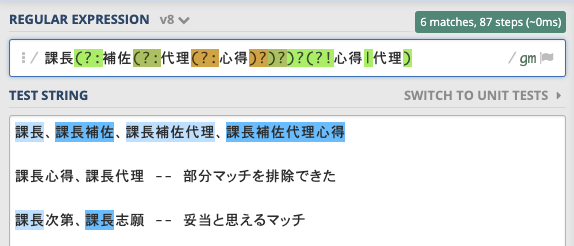
日本語の文字列でマッチの除外を手動で追加するのは手間がかかります。気をつけないと間違えそうです😅。

詳しくは以下の記事をご覧ください。
補足
ruby_regexp_trieは、PerlのライブラリであるRegexp::Trieから直接のヒントを得ています。作者は小飼弾氏です。
試していませんが、PythonやClosureなどにも同様の趣旨のライブラリがあります。
- リポジトリ: triegex · PyPI
- リポジトリ: noprompt/frak: Transform collections of strings into regular expressions.
これらの基礎にあるのは、Trie(トライ木)と呼ばれる、自然言語処理や機械学習方面で辞書向けによく使われるデータ構造です。こちらについてはそのうち別記事を書いてみたいと思います。
参考: トライ木 - Wikipedia
参考: 情報系修士にもわかるダブル配列 - アスペ日記
おたより発掘
Ruby: ruby-regexp_trie gemで文字列リストを効果的な正規表現に変換する
ほうほう、なるほどなるほど。
ありがとうございます🙇。