概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: How We Built A Multi-Tenant Job Queue System with PostgreSQL & Ruby
- 原文公開日: 2018/01/24
- 著者: Huy Nguyen
- サイト: Holistics Blog
RailsのPostgreSQL上でマルチテナントのジョブキューシステムを独自構築する(翻訳)
長期間運用されるプロセス(画像のリサイズ、レジュメのスキャン、負荷分析など)を必要とするWebアプリでは、バックグラウンドジョブキューシステムが重要になります。RabbitMQ(メッセージキュー)、Celery、ActiveMQ、Sidekiqなどのソリューションはよく設計されていて、業界でかなり人気を集めています。
本記事では、Ruby/Rails + Postgresを用いて弊社のB2B SaaSアプリ向けのマルチテナントジョブキューを設計/構築する方法をご紹介いたします。ここでは高度な問題についてその理由や解決のために行ったことを解説するとともに、理解を助けるためにいくつか特定のコードを見ていくことにします。
背景と要件
Holistics.ioはSQLベースのBIプラットフォームであり、データチームがエンドユーザー向けにレポートを自動ビルドする機能やダッシュボードの提供を支援します。小規模なスタートアップからテック業界の未上場企業/新規上場企業に至るさまざまなお客様にご利用いただいています。
バックエンドスタック構成:
- RubyとRails(PostgreSQLデータベース使用)
- haproxy、nginx、Unicorn
- Sidekiq(およびRedis): バックグラウンドジョブエンジンとして
しくみ: このプラットフォームで誰かがリクエストを送信するとSQLクエリが生成され、顧客のデータベースに送信され、結果を待ち、それを元にチャートが生成されます。
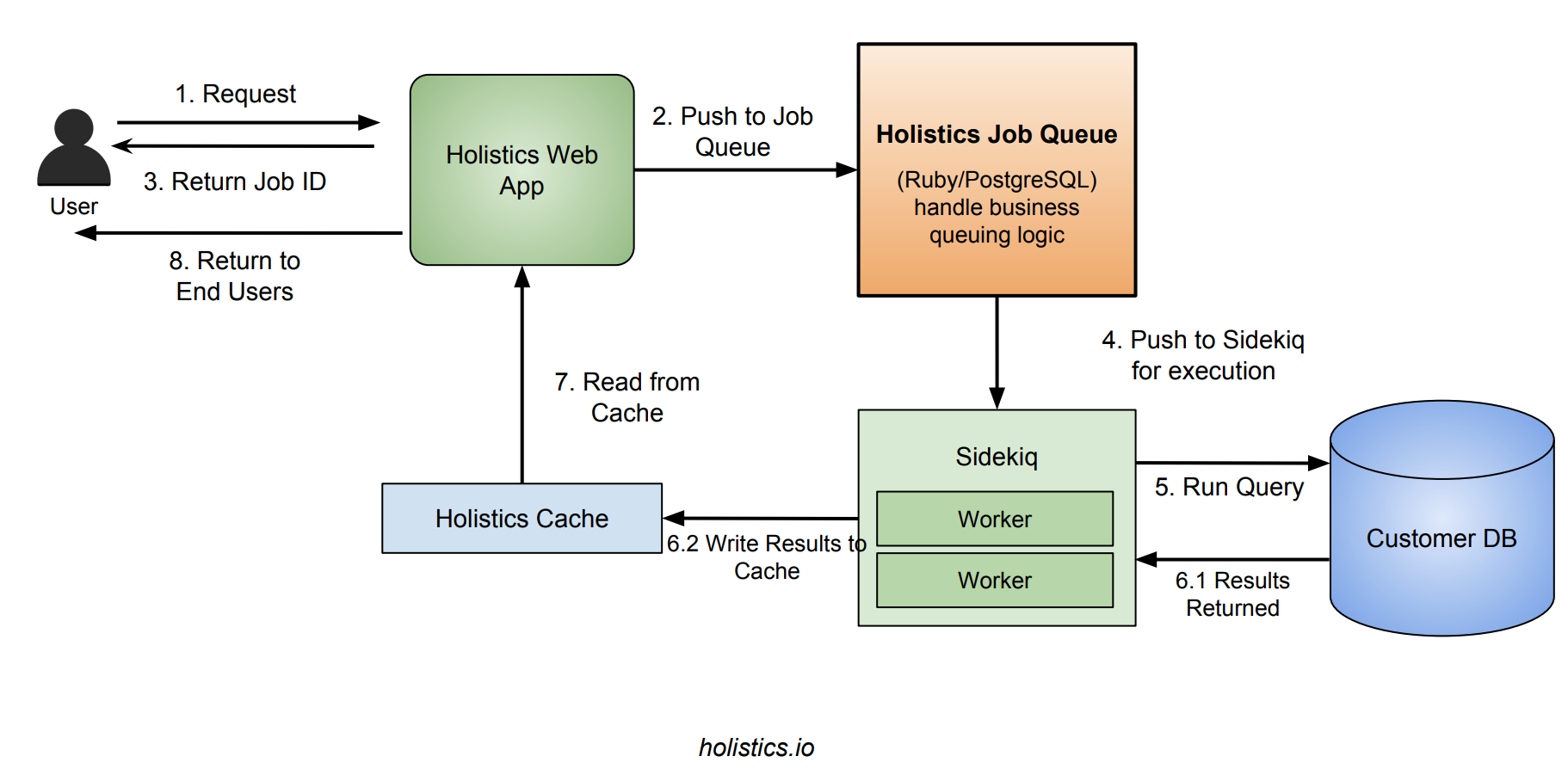
分析用SQLクエリの実行には時間がかかる(数秒から数分)ため、同期的なWebリクエストを使うのはよくありません。このため、リクエストを扱うバックグラウンドジョブキューシステムが必要になります。
弊社の場合、ジョブキューへの要件は次のようになります。
- ジョブの情報を永続化すること: バックグラウンドジョブごとに基本的な統計情報(ステータス、実行時間、開始時間、終了時間、結果レコード数など)をトラッキングする必要があります。
-
マルチテナントであること: 顧客ごとの独自ジョブキューは互いに影響を及ぼしてはならず、ジョブキューごとにサイズを変更可能であること(顧客Aは5つのスロットでコンカレントジョブを5つ実行でき、顧客Bは3つのスロットで3つのコンカレントスロットを実行できるなど)
-
信頼性: 顧客が必要とする分析はジョブキューに依存するため、ジョブキューは高い信頼性で実行できる必要があります。ジョブはキューに送信した順序で取り出されなければならず、かつ散発的に発生するエラー(ネットワークの問題など)を防ぐためにリトライメカニズムも必要です。
PostgreSQLでマルチテナントジョブキューを構築する
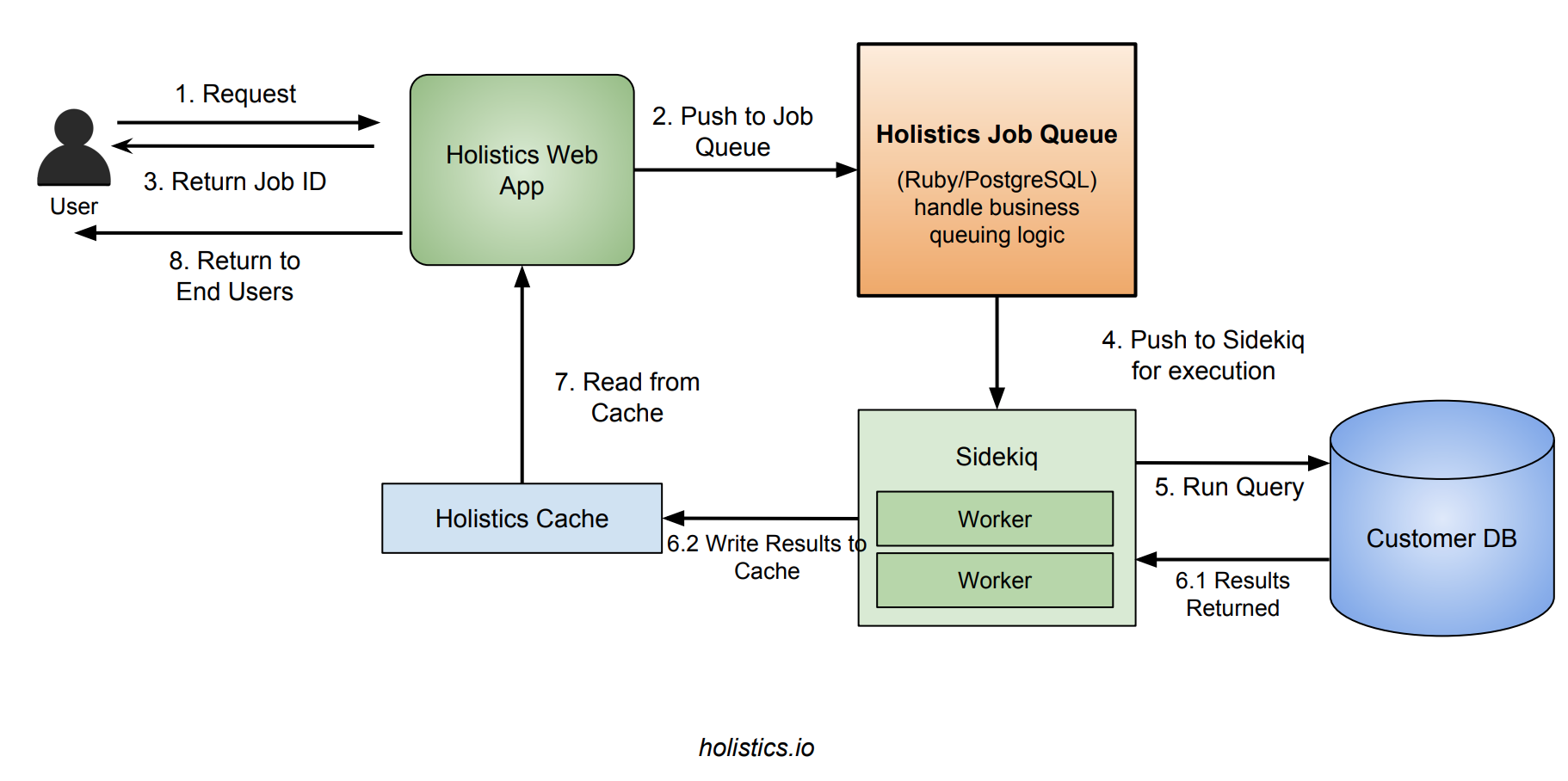
数回の開発を繰り返した後、Rails/RubyとPostgreSQLで構築されたジョブキューシステムが稼働しています。このシステムは、ジョブを管理したり、処理されるキューからジョブをピックアップしたりします。ピックアップされたジョブは、実際にバックグラウンド実行を担当するSidekiqに渡されます。
リクエストのワークフローは次のような感じになります。
- ユーザーがWebサーバーにリクエストを送信すると、Webサーバーは新規ジョブを作成してジョブキューエンジンにプッシュし、ジョブIDをクライアントに返す。
- ジョブキューエンジンは次に処理するジョブをピックアップし、Sidekiqにプッシュする。
- Sidekiqはジョブをピックアップして実行し、結果をキャッシュに書き込んで
jobsテーブル内のジョブステータスを更新する。 - クライアントは
successかerrorのいずれかになるまでWebサーバーにジョブのステータス問い合わせを繰り返す。successの場合はキャッシュから結果を取り出してクライアントに返す。
別のジョブキューを立てる理由とPostgreSQLを使う理由
PostgreSQL上に別のジョブキューシステムを実装することに頑張るのは「車輪の再発明」ではないかといぶかる方もいらっしゃるかもしれません。その主な理由(そして弊社のproductionデータベースであるPostgreSQLを使う理由)は次のとおりです。
- 永続性: 打ち上げ花火のような他のジョブキューシステムと異なり、弊社ではあらゆるジョブを統計情報やステータス付きでもれなく保管し、後で顧客にお見せする必要が生じます。そのためにはPostgreSQL上でジョブキューシステムを手作りするのが便利です。
-
独自のキューイングロジック: 弊社のスケジューリングロジックには多数のカスタムロジックが含まれているため、既存の他のジョブキューの利用方法が複雑になっています。上述のマルチテナンシーのロジックや、テナントのユーザーアカウントごとに最大コンカレントジョブ数の上限を設定するロジックなどが含まれます。
既存のジョブキューシステムを流用して要件を満たそうとすると、上の2つがさらに複雑になります。
一方、この方法にはいくつかのデメリットがあることも認識しています。
- スケーラビリティ: コンカレントリクエスト数が増加したときに水平スケールできません。ただしB2Bアプリにおける増加は、B2Cほど極端にはならないはずです。
-
パフォーマンス:
jobsテーブルが肥大化すると(弊社では実際に肥大化しました)、ジョブのキューイングロジックが遅くなる可能性があります。しかし適切なインデックス化とDBメンテナンス/チューニングを行えば乗り切れます。弊社では同時にテーブルのパーティショニングも行って、アクティブなデータセットが小さくなるようにしました。
ジョブの保存と送信
ユーザーがリクエストを1件送信するときに、ジョブごとのメタデータを保存する何らかのしくみが必要です。そのためのjobsテーブルを作成しました。
CREATE TABLE jobs (
id INTEGER PRIMARY KEY,
source_id INTEGER,
source_type VARCHAR,
source_method VARCHAR,
args JSONB DEFAULT '{}',
status VARCHAR,
start_time TIMESTAMP,
end_time TIMESTAMP,
created_at TIMESTAMP,
stats JSONB DEFAULT '{}'
)
弊社の設計では、ジョブのステータスは以下の値を取ることができます。
created: 最初に作成されたときqueued: ピックアップされてSidekiqにプッシュされたときrunning: Sidekiqワーカーがジョブをピックアップして実行を開始したときsuccess: ジョブが成功したときerror: ジョブが失敗したとき
ここで興味深いのは、弊社のキューレイヤーが本質的に二重である(独自の論理ジョブキューとSidekiq、後者も本質的にはジョブキュー)ため、ジョブのステータスにcreatedとqueueの両方を用意していることです。
start_time - queue_timeはゼロに限りなく近い最小値になる必要がありますが、この数値が増加すると(ジョブがSidekiqにプッシュされたが、ジョブを扱うSidekiqのワーカー数が不足している場合)、Sidekiqワーカー数を増やす必要が生じていることがわかります。
PostgreSQLでジョブキューロジックを扱う
ジョブキューシステムでは以下のサポートが必要になる可能性があります。
- 実行可能が「宣言」(claim)されていない次の実行可能ジョブを検出して宣言する機能
- 2つのプロセスが同じジョブを実行可能と宣言できないようにする機能、および各ジョブが(正確に1度だけ)最終的に必ず実行されるようにする機能: これは見かけよりずっと困難であることがわかりました
- 不測の事態(ネットワーク障害やワーカーノードの障害)によってジョブの処理がなぜか失敗した場合に、ジョブのロジックが失敗せずにジョブを元のキューに戻す機能
PostgreSQLや、上述の制約をサポートするSQLを用いてジョブキューを構築するのは、想像以上に困難であることがわかってきました。主な困難としては、ジョブをtakenとしてマーキングした後、ワーカーが何らかの理由(タイムアウト、メモリ不足、ネットワーク障害など)でジョブの処理に失敗したときにジョブが解放され、ジョブが失われてしまう流れを解明できなかったことです。
弊社ではいくつか別のアプローチを試した結果、PostgreSQL 9.5の機能であるSKIP LOCKEDにたどり着きました。この機能はこの目的に特化した設計になっています。詳しくはCraig Ringerの記事「What is SKIP LOCKED for in PostgreSQL 9.5?」をご覧ください。
考え方は次のとおりです。
- ある1つのトランザクション内で、これまでロックされたことのない利用可能な次の行を取得するSQLクエリを作成し、続いてそこに行レベルロックをかけ、トランザクションが続いている間ロックを保持する(この間、宣言は有効)と、他のプロセスはその行に対して宣言できなくなる。
- ジョブが成功したら、行のステータスを更新して
successにし、トランザクションを終了する。 - プロセスがクラッシュしたら、トランザクションは自動的にabortされ、行の宣言は取り消される。
この後に実際のコードを掲載していますのでご覧ください。
マルチテナンシーのサポート
さらに弊社の場合、要求されるキューが顧客ごとに異なっています。これは、以下のような(tenant_id)が一意のテナントキューテーブルで表現しました。
CREATE TABLE tenant_queues (
id INTEGER PRIMARY KEY,
tenant_id INTEGER,
num_slots INTEGER
)
ジョブ重複防止とリトライのメカニズム
ユーザーがレポートページでうっかり更新ボタンをクリックしたために、新しいジョブが生成されてバックグラウンドに送信され、システムで不要な過負荷が生じるという問題がたびたび発生していました。
このために、ジョブ重複防止のメカニズムも構築しました。ジョブ送信のたびにジョブが一意かどうか(ジョブが生成するDBへのクエリが同一かどうか)をチェックします。このチェックは、ジョブ送信後に10分間、未終了のジョブに対して行われます。重複が検出された場合は、単に古いジョブIDを返します。
同様に、リトライメカニズムも追加しました。これはプロセスがクラッシュした場合(メモリ不足などの不測の事態)にジョブを自動で再実行します。再実行する最大ジョブ数は設定可能です。
コードをひととおり眺めてみる
基本的に次のSQLで考えてみます。最初に利用可能になる次のジョブ(作成順)を検出するクエリです。クエリのテナントにはスロットの空きがまだあり、誰もジョブの実行を宣言しておらず(SKIP LOCKED)、自分自身で宣言しています(FOR UPDATE)。
-- キューがいっぱいかどうかを調べるため、キューごとに実行中のジョブ数を検出する
WITH running_jobs_per_queue AS (
SELECT
tenant_id,
count(1) AS running_jobs from jobs
WHERE (status = 'running' OR status = 'queued') -- runningまたはqueued
AND created_at > NOW() - INTERVAL '6 HOURS' -- 6時間以上実行されているジョブは無視
group by 1
),
-- いっぱいになったキューを検出する
full_queues AS (
select
R.tenant_id
from running_jobs_per_queue R
left join tenant_queues Q ON R.tenant_id = Q.tenant_id
where R.running_jobs >= Q.num_slots
)
select id
from jobs
where status = 'created'
and tenant_id NOT IN ( select tenant_id from full_queues )
order by id asc
for update skip locked
limit 1
ここでは、次のジョブをピックアップして実行のためにSidekiqに渡すqueue_next_job()メソッドを定義します。このメソッドはトランザクションにラップされる点にご注意ください。これはステータスをqueuedに更新している途中で他のプロセスがジョブに対して「宣言」できないようにし、絶対に2回ピックアップされないようにするためです。
class Job
def queue_next_job()
ActiveRecord::Base.transaction do
ret = ActiveRecord::Base.connection.execute queue_sql
return nil if ret.values.size == 0
job_id = ret.values[0][0].to_i
job = Job.find(job_id)
# バックグランドワーカーに送信
job.status = 'queued' && job.save
JobWorker.perform_async(job_id)
end
end
end
弊社側のJobWorker(Sidekiqによって実行される)では、単にステータスをrunningに設定して実際に実行します。
# 簡略化したコード
class JobWorker
include Sidekiq::Worker
def perform(job_id)
job = Job.find(job_id)
job.status = 'running' && job.save
obj = job.source_type.constantize.find(job.source_id)
obj.call(job.source_method, job.args)
job.status = 'success' && job.save
rescue
job.status = 'error' && job.save
ensure
Job.queue_next_job()
end
end
queue_next_job()がensureブロック内で呼ばれている点にご注目ください。スーパバイザープロセスがキューを監視していることが多い他のジョブキューシステムと異なり、ピックアップしたジョブを次の空きワーカーに渡しています。弊社の場合はスーパバイザー/ワーカーという概念を用いていないので、現在のジョブ終了直後にqueue_next_jobを呼ぶことで現在のワーカーをシンプルに利用し、バックグラウンドワーカーの実行はSidekiqに任せています。
| 他のジョブキュー | 弊社のジョブキュー | |
|---|---|---|
| マスター | 専用プロセスでリクエストを受信 | 既存のRailsまたはSidekiqプロセスによるSQL + インライン |
| ワーカー | 専用のプロセスまたはスレッド | Sidekiqに渡す |
Sidekiqについてのメモ: Sidekiqは素晴らしいバックグラウンドジョブワーカーシステムです。弊社ではこれまでSidekiqを利用してきましたし、今後も利用するでしょう(実際、弊社は有償ユーザーです)。弊社のPostgreSQLジョブキューはSidekiqの上で動作し、ジョブのビジネスロジックをより精密に扱う一方、Sidekiqは実際のジョブ実行を担当します。
また、弊社のジョブの性質(実行時間が極めて長く、メモリ不足が生じる可能性がある)のため、プロセスレベルモニターの追加と、Sidekiqプロセスでのメモリスレッショルド管理メカニズムの追加についてSidekiqにいくつかアドバイスを送りました。これについて別記事でご紹介できればと思います。
バックグラウンドジョブのロジックを抽象化する
弊社のジョブシステムの一部として、Rubyにある.asyncメソッドチェインを導入しました(Rubyのメタプログラミングを活用しています)。このメソッドによって同期と非同期を極めてシンプルに切り替えることができます。
以下のコードでは、DataReport#executeは1回書き込み可能で、同期的に実行することも非同期的に実行することもできます。
report = DataReport.find(report_id)
# 通常: 同期的に実行(`execute`メソッドの戻り値を返す)
report_results = report.execute
# 非同期実行(整数のジョブIDを返す)
job_id = report.async.execute
これによって、Sidekiqを利用するオブジェクトからSidekiqを完全に隠蔽することもできるようになりました。別のバックグラウンドワーカーシステムをサポートする新しいアダプタも簡単に書けます。この手法がJavaScriptの「Promise」のコンセプトに似ている点にご注目ください。
さらに、上述のjobsテーブルの(source_type, source_id, source_method)という組み合わせにもご注目ください。これは基本的にはポリモーフィズムであり、ジョブを分割してシームレスに別の種類のジョブにする方法です。
まとめ
本記事では、RubyとPostgreSQLとSidekiqを用いたマルチテナントのジョブキューシステムを独自設計した理由とその方法について解説いたしました。完成したジョブキューシステムは柔軟性も信頼性も高く、弊社の要件を満たしています。
- 送信されたジョブが
jobsテーブルで永続化されるようになったので、分析や顧客への公開がやりやすくなった - キューイングロジックがマルチテナントで扱えるようになったため、顧客ごとの独自キューが互いに干渉しなくなり、CPUリソースの共有が進んだ
- コードが適切に抽象化されたことで、開発しやすくなった
今回の作業で、ジョブキューやPostgreSQLのロックメカニズム、そしてRubyのメタプログラミングについて多くのことを学べました:)!
お気づきの点やご意見/ご感想がありましたら、お気軽に原文末尾のコメント欄までどうぞ。