morimorihogeです。今年もTechRachoアドベントカレンダーを実施します。TechRachoを運営している弊社(BPS株式会社)及び弊社にご縁のある会社・個人の記事を公開していきますので、皆様お楽しみに!

さて、僕は職位としてはマネージャ職に当たりますが、良くある開発チームの例に漏れずちょいちょいチームの手が足りない所ではプロジェクト管理や設計、実装に入ったりすることもあります。上流から実装・運用までやるいわゆるなんでも屋ですね。
そんな中で上流設計・要件定義を詰めていく役割もよくやることがあるので、今回はその辺りの内容がテーマです。
開発現場のエンジニアはもちろんですが、ビジネスサイドでエンジニアチームに機能要望を出したりする人にもぜひ読んで欲しいと思いながらまとめていこうと思います。
サービスメンテナンス機能
今も昔も割とふわっとした要望をもらうことが多いのが「サービスメンテナンス機能」です。
いわゆる「このサイトはメンテナンス中です」的な画面を出して、ユーザーが一時的にサービスを使えない状態にさせる機能ですね。
昨今のWebサービスでは何事もなければ24h/365d常時稼働することが求められるのが常態化していますが、現実にサービスを運用していると大規模な機能更新やインフラ更新のためにサービスを計画的に一次停止することがあるのが普通です。
サービスメンテナンス機能についてはそもそも最初の要件定義には存在しなくて後から追加するケース、最初から要件に入っているケースの両方を見ますが、たいていの場合あまり深く要件が詰められていません。
要件定義の際はサービスが実際に価値を出す部分の機能に注力するので、こういったユーザーから内部の処理が見えにくい機能についてはどうしても力が入りづらいのですね。
ただ、簡単に見えるサービスメンテナンス機能も、よく考えると色々と奥が深いです。この辺りを僕の経験から詰めていってみようと思います。
計画停止のための機能なのか、障害時のための機能なのか?
計画停止というのはシステムのアップデートなど、あらかじめ予期したスケジュールで対応するケースです。大規模なテーブルロックが避けられないデータベースの更新や、冗長系を用意できない状態でのインフラアップグレード対応、そもそもシステムとしての稼働時間をあらかじめ決めておくようなケース(e-Taxの利用可能時間なんかはやや複雑です)などが該当します。
このケースではシステムとしては正常系として設計するので設計の自由度があります。
障害時というのは予期しない理由でサービスが応答できなくなったときに出す画面を想定しています。本来はシステム側からエラー応答を返したいところですが、それもままならない時のための機能という扱いになります。具体的にはロードバランサのデフォルトエラー画面を返したくない場合などが相当します。
- 計画停止のための機能の場合
- メンテIN/OUTを運用者が切り替えるための仕組み(管理画面など)
- メンテIN/OUTは手動で行うだけで良いのか、あらかじめスケジュールを設定して自動で行う必要があるのかの検討
- 計画停止としてどのレベルまで停止できるようにするのかの決め(後述)
- 障害時のための機能の場合
- そもそもの障害として考慮する範囲の洗い出し(後述)
- どの程度詳細な障害内容を伝えるのかの検討(ユーザーからの問い合わせ対応に影響する)
- 障害発生時の運用者への通知機能や障害範囲が分かるようなモニタリング範囲の決め
どのレベルのサービス停止を想定するのか?
昨今のシステムは単体のサーバーから返すということはごくまれで、CDNなどのエッジサーバー、バックエンドAPIサーバーなど多くのシステムに依存しています。
そのため、サービスメンテナンス機能もどのシステムのメンテナンスを想定するのかで設計が変わってくることになります。
特に、インフラとしてどのポイントから停止してよいのかはよく検討しておかないとそれより前段のメンテナンスには使えなくなってしまうので注意したいものです。
例を挙げてみましょう。よくあるエッジサーバー(CDNなど)+アプリケーションサーバー+基幹系のシステムを想定したとき、アプリケーションエンジニアであれば下図のようなサービスメンテナンス機能を思いつくと思います。
アプリケーションサーバーのメンテナンスができるように、エッジサーバーの向け先をメンテナンス系に向けることでサービスメンテナンス画面を出させるという構成です。
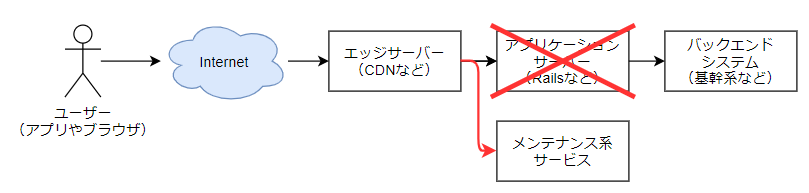
一見何の問題もない設計に見えますが、このケースではエッジサーバー自体のメンテナンスには対応できないということが分かります。
昨今ではAWS Lambda@EdgeやCloudflare Workersなど、CDN等のエッジサーバーでもある程度の処理を実行できるようになっていますが、こうした部分での障害や計画停止(商用CDNの場合、停止はないと思いますが)メンテナンス画面を出したい場合には、エッジサーバー自体を切り替えるような設計にしてやる必要があります。
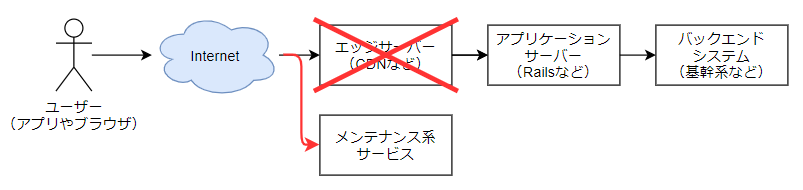
こうした考慮は特に障害系のメンテナンス画面を設計するときに考慮が必要な部分になります。計画停止であればある程度前もってユーザーに告知したり、当初設計していないインフラの切り替えでもその時のためだけのメンテナンス系を一時的に用意したりすることができますが、障害はいつ起こるのか分からないのであらかじめ考慮して設計しておく必要があります。
基本的にエッジサーバーは外部のサービスを使うことが多く、そうしたサービスでは高いSLAが約束されていることが多いですが、今年6月に発生したFastlyの障害のようなことは数年に1度くらいの周期では発生します。
現実的にここまで設計上考慮する必要があるケースは少ないとは思いますが、障害発生点の洗い出しという点でもこの辺りの設計については要件定義時に非機能要件として記載しておくのをお勧めします。
サービスメンテナンスの影響範囲の洗い出しと確認
計画停止の場合、特に注意して確認する必要のある観点になります。
ブラウザから閲覧する環境だけを提供しているシステムであれば普通にメンテナンス画面を返すだけで問題ありませんが、昨今のWebアプリではiOS/Androidのモバイルアプリ向けのAPIサーバーを兼任していることが多々あります。
こうしたケースでJSONやXMLなどを期待しているモバイルアプリがあった場合、想定外の動作をする可能性があります。
Webアプリ側の開発とモバイルアプリの開発は別チームで進めるケースがそれなりにあるため、このあたりの認識に齟齬がないかは確認しておく必要があるでしょう。
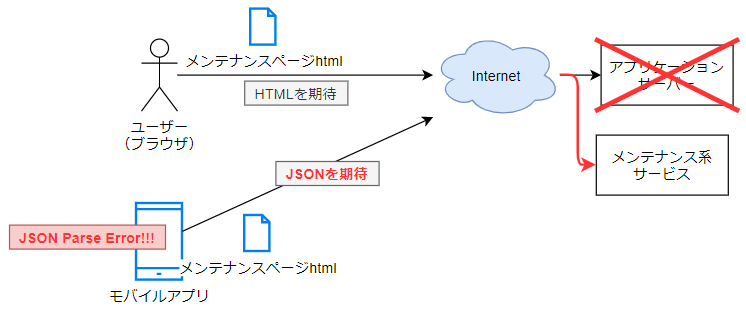
一般的にはHTTP Statusをきちんと200以外のエラーとして返してやることでアプリ側でもサービスメンテナンス中であることを判別できるようにするというのが対策になると思います。
あとは、モバイルアプリ以外だと、コンテンツ配信系のサイトの場合にはメンテナンス画面で200 OKを返してしまうと検索エンジンのインデックスが全部メンテナンスページに書き換わってしまうという地獄を見ることがあります。
昨今ではWebアプリだけでもフロントエンドとバックエンドの分業が進んでいたりと1つのシステムに複数のチームが関わることが増えましたが、システム全体を俯瞰して見られる人がいないとこの辺りを見落としがちなので、気を付けたいところです。
ユーザーに見せる画面(その後のシナリオ)をどうするのか?
意外と要件定義で見落とされがちな部分です。
サービスメンテナンス機能は「サービスメンテナンス画面」を出すという要件だけ決めて進めることが多く、具体的なメッセージ内容については後回しになりがちです。
もちろん表示するメッセージ文言そのものは要件定義時に完全に固める必要はありませんが、ユーザーにどのようなネクストアクションを案内すべきかは要件定義で考慮すべきです。
最も簡単な例だと単純に「メンテナンス中です。しばらく時間をおいてアクセスしてください」といった汎用メッセージを出すケースが考えられますが、サービスメンテナンス中でもどうしてもアクセスしたいユーザーがいる可能性は考慮したいです。特に、ユーザーが現地で当該サービスを使うような場合や時間制限のあるサービスの場合、汎用メッセージではユーザーはとても困ります。
航空券予約サイトでQRコードチェックインしようと思ったらエラー画面で見られない、コンサート会場のゲートでチケット画面がエラーで見せられない、大学の履修申告締め切り時間前なのにエラーで見られないなど、汎用エラー画面ではユーザー体験に致命的な問題を及ぼす可能性があります。
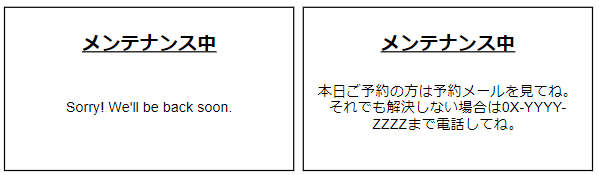
実際の運用では既にユーザーへ送ったメール履歴を使ってもらうことで現地対応は何とかなったり、別途サポート窓口に電話してもらうなどでなんとかすることが多いと思いますが、そうした案内をメンテナンス画面に出せるように考慮しておく必要はあります。
こうしたユーザーシナリオを考慮していくと、電話サポート窓口はコストがかかりすぎるので別のサービスで障害時受付の完全別建てのWebシステムを用意しようといった追加要件につながることもあります。
サービスメンテナンス機能を見せられたユーザーがそのあとどうすればいいのかという視点はシステムのことだけ考えていると見落としがちなので、要件定義のタイミングで一歩振り返ってみることをお勧めします。
まとめ
そんなわけで、ふわっとした要件を投げられたときにどんな観点でヒアリングをしているのかの例を出してみました。単純に見えるサービスメンテナンス機能でも、ふわっと投げられると色々考慮すべきことは多いんだよという例になれば幸いです。
ここに挙げたことは上流設計を行うビジネスサイドが考えるべきことだという意見もあるかもしれませんが、システムの構成に関わる考慮事項などはエンジニアでないと指摘できないことも多々あるのでエンジニア側も積極的に要件定義段階から参加していくべきでしょう。
一方で、エンジニア側から指摘してもビジネスサイドでは判断できないというケースもあります。特に新規サービスの場合、作りながら考えていくことも多いため「決めてほしい」といっても「うーん、決められないからいい感じにやっておいてよ」となることもまたあるあるです。ただ、こうした場合であってもあらかじめリスクをチーム全体で共有しておくことは後々の認識齟齬を防ぐためにも価値があることだと思います。
今回のような要件定義ターゲットにした記事は気が向いたらまた書いていこうと思うので、もし次があればまたお付き合いください。ではでは
停止すると人が物理的に傷ついたり重大な財産を失う可能性のあるようないわゆるミッションクリティカルシステムについては無停止が要求されますが、そうしたシステムは全体として無停止でも冗長系を用意したり、切り替えのための仕組みを用意するなどして個々のシステムとしてはメンテナンスできるように最初から設計されています。
そして、その冗長系の運用や切替のためのテスト等には多大なコスト(インフラ・人件費・時間)をかける必要があります。
昨今ではシステム設計もある程度ベストプラクティス的なテンプレートができ、DR(Disaster Recovery)構成なども事業継続の観点から話題に上がるようになりましたが、それでもシステムの可用性を上げるには多大なコストがかかります。
「言うは易く行うは難し」の筆頭が無停止設計なので、もし要件定義の際に例外条件なしの常時稼働要件が入っていた場合には我々エンジニア側からきちんとヒアリングした方が良いでしょう。冗談抜きで開発・運用の見積が倍以上変わってきます。