こんにちは。yoshiです。
先日(9月1日)にオープンされた TypeScript のプルリクエストがヤバいわよ!という話をします。
※※※注意ここから※※※
一応先に言っておきますと、これからする話はまだ PR 段階なのでそのまま取り込まれるかどうか分からないし、どのバージョンでリリースされるかも分かりません。ここで書いていることはリリース時には仕様が変わっている可能性は大いにあり、リリース後に検索等でこの記事にたどり着いた方は、もっと良い解説がどこかにあると思うのでそちらを参照することをおすすめします。
※※※注意ここまで※※※
該当の PR はこれです。
この PR には2つの機能が含まれているのですが、そのうちの一つ、 Template string types というのが強力です。強力すぎて遊んでみたら楽しかったのではしゃぎながらこの記事を書いています。
JavaScriptには Template literal という機能があって、 `` で囲んだ文字列の中に ${x} のように値を埋め込むことができます。
例えば、
const x = 'bar';
const y = `foo${x}baz`;
とすると、 y の値は "foobarbaz" という文字列になる、そんな機能です。
Template string types は、この Template literal を型の世界に取り込んだような機能で、何ができるかと言うと型レベル文字列操作ができます。ヤバいですね。
Template string types で先程の例と同じようなことをやると、
type X = 'bar';
type Y = `foo${X}baz`;
これで Y は "foobarbaz" という文字列リテラル型になります。ヤバい。これで何ができるかと言うと、まずプロパティ名が合成できます。 foo から getFoo を合成できたりする訳ですね。 foo から getFoo は単純な文字列結合だけでは不可能なので、そのために case を変更する機能も付いていて、 `${capitalize 'foo'}` が "Foo" になったりするようです。ヤバいですね。
はい。これだけでもヤバいですが、この機能、強力な型推論も付いていて、こちらを使うと本当に色々できてしまいます。こちらが本題。
既存の型推論というのは、 Conditional type で
A extends [infer B] ? B : never
のように書くと、 A が [T] であったときに B が T に推論されるような機能でした。言い換えると、 A が [T] のとき、 A extends [B] を満たすような B の型の、なるべく制約の多い物(制約が緩くて良いのであれば全部 any になってしまいます)を探す処理が型推論である、と言えます。
Template string types にも同じように型推論ができるような機能があって、
A extends `foo${infer B}baz` ? B : never
のように書くと、 A が "foobarbaz"だったとき、 B は "bar" に推論されます。ヤバさが伝わりますでしょうか。つまり、これは パターンマッチで文字列分割ができる ということに他なりません。
残念ながら、「任意のUnicode1文字にマッチするパターン」みたいなものはないので、任意の文字列リテラルを1文字ずつ分割することはできません。ただし、特定の文字しか登場しない文字列リテラルなら、あらかじめ登場する文字を列挙しておけば1文字ずつに分割できます。
これが何を意味するか。
例えば BrainF**k のような「ソースコードに特定の文字しか登場しない言語」ならパーサーを書くことすらできます。「TypeScriptコンパイル時 BrainF**k インタプリタ」を作れる訳ですね。再帰深度の制限が厳しいのでそのままで動く訳ではないようですが、既に作っている方もいます。
数値文字列の分割
BrainF**k すら作れるならまあ大体何でも作れるだろうな、という感じではありますが、ここからは今までやろうとしても再帰深度に引っかかったりして断念していたあれこれを実装していきたいと思います。ポイントは数値文字のみで構成された文字列を分割すること、つまり整数リテラルを文字列リテラル化して、1桁ずつ扱うことです。
ちなみに整数リテラルの文字列化は N extends number に対して `${N}` とするだけで書けます。 `${42}` と書けば "42" になる訳ですね。
という訳で、とりあえず数値文字列を扱うために、
- 先頭1文字を取り出す
First型 - 先頭を取り除いた残りの文字列を返す
Tail型
を用意しようと思います。こうです
type Digits = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9;
type Tail<T extends string> = T extends `${Digits}${infer U}` ? U : never;
type First<T extends string> = T extends `${infer U}${Tail<T>}` ? U : never;
任意の大きさの Tuple の生成
TypeScript の Tuple は、各要素の型が指定された固定長の配列です。 Tuple の実体は JavaScript の配列そのもので、 TypeScript では型を付けているだけに過ぎません(まあ TypeScript の大部分の機能は型を付けているだけと言えるのですが)。
Tuple の定義は、 JavaScript の配列を書くときと同じように [T1, T2, T3] などと書くことで作ることができます。ここで例えば T を1000個並べた Tuple を作りたい、となった時に、愚直に書けば [T, T, T, (994個省略), T, T, T] などと書かなければいけない訳ですが、これは流石に手で書きたくはありません。コードを自動生成することもできなくはないですが、ソースコードにそんなものが書いてあるのもどうかと思います。
なお、「そもそもそんなでかい Tuple を定義をする機会なんてまず無いだろう」というツッコミが来そうですが、気にしないことにします。ぶっちゃけ、そういうのを簡単に作れたら楽しいよねってだけなので。
実際のところ、単に大きな Tuple を作るだけなら、 Template string types を使わなくても可能です。ここらへんは TypeScript 4.0 以降とそれまででも事情が異なっていて、 TypeScript 4.0 では [...T, ...T] のような記法が可能になったので、この場合は任意の Tuple を2回繰り返した Tuple が生成できるようになっています。これを利用すれば、倍々ゲームで大きい Tuple を作ることができるので、例えば 2^n サイズの Tuple とか 10^n サイズの Tuple などを作るのはそう難しくありません。そして、それらを合成することで、例えば長さ1234の Tuple を作りたかったら、
![]()
なので、そういう大きさの Tuple を生成してから合成すれば作れる、ということになります。
なお、 TypeScript 4.0 以前では、 Parameters<(a: T, ...b: U) => void> が [T, ...U] になることを利用して Tuple に型を追加することが可能でしたが、 [...T, ...T] が一気にサイズを2倍にできるのにたいして、 [T, ...U] ではサイズが1個しか増えない([T, T, ...U] などのようにして一度に2個以上増やすことは可能ですがいずれにしても線形に増加する)ため、これを再帰的に適用して Tuple を生成しようとするとすぐに再帰回数の制限に引っかかって、大きな Tuple を生成するのは困難でした。
ここでは解説しませんが、 TypeScript 4.0 でも頑張れば任意のサイズの Tuple を作ることが可能です。ただし、 TypeScript 4.0 でこれをやろうとすると、内部で配列のコピーが無駄に多く発生してしまい非効率で、再帰が多くなってしまい途中で限界に達していたのが、 Template string types を利用することでかなり効率よく書けるようになったので、その成果を置いておこうと思います。
文字列を整数に変換するアルゴリズム
Tuple のサイズ拡大は [...T, ...U] のように2つの Tuple を合成する操作や、 [...T, ...T, ...T] などのように 1つの Tuple を複数回合成する操作を通して行います。これは、それぞれの Tuple を自然数の射とみなした場合に、それぞれ加算と定数倍に相当する操作です。
加算と定数倍(この場合は0倍から10倍まで)ができれば、10進文字列を整数に変換するアルゴリズムが書けます。つまり parseInt を実装するのと同じようにできる訳です。試しに parseInt を書いてみると、
function parseInt(src: string): number {
let x = 0;
for (const ch of src) {
if (ch < '0' || '9' < ch) {
return NaN;
}
x = x * 10 + ch.charCodeAt(0) - '0'.charCodeAt(0);
}
return x;
}
こんな感じになります(負の数や基数を考慮していないので組み込みの parseInt と挙動は一致しません)。for 文を使ったアルゴリズムはこのまま型に適用することはできないので、再帰に変更すると、
function parseInt(src: string, x: number = 0): number {
if (src == '') {
return x;
}
const ch = src[0]; // First
if (ch < '0' || '9' < ch) {
return NaN;
}
return parseInt(
src.slice(1), // Tail
x * 10 + ch.charCodeAt(0) - '0'.charCodeAt(0),
);
}
こんな感じになります。 First と Tail は上で実装済みなので、 x * 10 + ch.charCodeAt(0) - '0'.charCodeAt(0) の部分を実装すれば良いです。
Tuple のサイズを定数倍する
x *10 の部分で Tuple のサイズを10倍にする必要があるのと、 ch.charCodeAt(0) - '0'.charCodeAt(0) の部分は0~9のいずれかの値になるので、 length が0~9の Tuple を生成することができる必要があります。ここは力技で、こんな型を用意します。
編集部注: シンタックスハイライトのためここだけGistにしました。
まあ、解説するまでもありませんね。単純に並べているだけです。
これで、 x*10 の操作は Tile<X, 10> にできますし、 ch.charCodeAt(0) - '0'.charCodeAt(0) の部分は Tile<[T], Ch> みたいに書くことができます。
parseInt のアルゴリズムを Tuple に適用して MakeTuple 型を作る。
ここまで来たらあとは簡単です。
type First<T extends string> = /* 上記参照 */;
type Tail<T extends string> = /* 上記参照 */;
type Digits = /* 上記参照 */;
type DigitsStr = /* 上記参照 */;
type Tile<T extends unknown[], N extends Digits | DigitsStr | 10 | '10'> = /* 上記参照 */;
type MakeTupleImpl<T, N extends string, X extends unknown[] = []> =
string extends N ? never : // 文字列リテラルじゃなくて string 型が渡ってきた場合は変換できない
N extends '' ? X : // if (src == '') { return x; }
First<N> extends infer U ? U extends DigitsStr ? // const ch = src[0]
MakeTupleImpl<
T,
Tail<N>, // src.slice(1)
[ ...Tile<[T], U>, ...Tile<X, 10> /* x * 10 */]
>;
export type MakeTuple<T, N extends number> = MakeTupleImpl<T, `${N}`>;
上の parseInt アルゴリズム内の同じ処理に相当する部分にコメントを付けてみました。
デフォルト値を渡している第2引数を隠蔽したかったのと、引数として number 型以外を受け取らないようにしたかったので、 公開する MakeTuple と内部で使う MakeTupleImpl に分割しています。

長さ10000の Tuple でも簡単に作れます。やったね! 10000000くらいまでは時間がかかりますがなんとか生成できるようです。
この方式では、再帰深度は数値の桁数+α程度です。 TypeScript の再帰深度上限は50らしいですが、64ビット整数でも10進数にすると19桁なので、大きすぎる Tuple を作ると再帰深度上限にひっかかる前にメモリ不足で JavaScript エンジンが死にます。
自然数の文字列リテラルから数値リテラルへの変換
Template string types では `${T}` とすることで数値→文字列への変換は可能ですが、一方で文字列→数値の変換はできません。
ただし、 Tuple のlengthが数値リテラル型であることを利用して、文字列から Tuple を生成してその length をとることによって(かなり効率は悪いものの) 文字列→数値の変換ができます。
export type ToNumber<S extends string> = MakeTupleImpl<unknown, S>['length'];
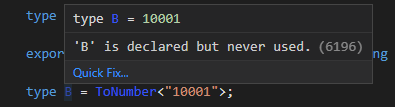
IndexSequence の生成
MakeTuple と ToNumber を使えば、 C++にある index_sequence と同じようなものを生成することもできます。これは [0, 1, 2, 3, ..., N] のようにN番目の要素がNになっている Tuple です。まずサイズNの Tuple を生成して、 Mapped Type を使うと各要素のキーが数値文字列になっているので、それを ToNumber で変換します。
type IndexSequenceImpl<T extends unknown[]> = {
[K in keyof T]: K extends string ? ToNumber<K> : never;
}
export type IndexSequence<N extends number> = IndexSequenceImpl<MakeTuple<unknown, N>>;

ToNumber の効率が悪いのは上記の通りなので、この方法だとかなり重く、1000要素程度で重くなり10000要素で失敗しました(画像の例も重いので控えめに)。なお、数値リテラルに変換することにこだわらなければ、単に Mapped Type でキーに置き換えればいいだけなのでだいぶ軽くなります。
type StringIndexSequenceImpl<T extends unknown[]> = {
[K in keyof T]: K;
}
export type StringIndexSequence<N extends number> = StringIndexSequenceImpl<MakeTuple<unknown, N>>;

終わりに
というわけで、 Template string types の表現力がヤバいことが分かっていただけましたでしょうか。
今回はここまでにしますが、他にも
IndexSequenceを利用して Tuple の Slice を作成- 数値文字列同士の比較演算や四則演算の実装
など、やろうと思えばできることがたくさんあるはずです。興味が湧いたら試してみると面白いかもしれません。
今記事のコードはこちらで試すことができます。
