概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: How to scale PostgreSQL 10 using table inheritance and declarative partitioning
- 原文公開日: 2017/11/09
- 著者: Matvey Arye
- サイト: http://www.timescale.com/ -- オープンソースの大規模時系列データベース「timescaledb」を開発する企業です。
timescale.comより
PostgreSQL 10: テーブル継承と宣言的パーティショニングでスケーリングする(翻訳)

PostgreSQL 10がついにお披露目されました(原注: 本記事執筆後間もなく10.1がリリースされました)。PostgreSQL 10のリリースは、論理レプリケーション、JSONやJSONBでの全文検索サポート、クロスカラム統計、並列クエリのサポート強化といった根本的な新機能を含んでおり、いろいろな意味でエキサイティングです。全般に、PostgreSQL 10は賞賛に値するオープンソースデータベースとして着実な進歩を重ねており、その大きなマイルストーンと言えます。
PostgreSQL 10の素晴らしい新機能のひとつに、宣言的パーティショニング(declarative partitioning)があり、これによってPostgreSQLをビッグデータ級のボリュームにスケールさせることが本質的に簡単になります。
PostgreSQLをスケーラブルにすることは、将来の成功のために重要です。PostgreSQLでのスケーリングの難しさに、多くの開発者たちが長年不満の声を上げていました。その結果、スケーラビリティを約束する「NoSQL」ソリューション人気を博してそちらに流れる傾向が目立ち、みな熱心にNoSQLソリューションを採用したのです。しかしそうしたNoSQLのオプションは多くの場合、信頼性、パフォーマンス、使いやすさを犠牲にしていました(近年SQLに回帰する開発者が増えた理由のひとつがこれです)。
宣言的パーティショニングによって、PostgreSQL 10の基礎部分はこうした他の技術と渡り合えるようになりました。宣言的パーティショニングは、PostgreSQLが提供すべき堅牢さ、信頼性、強力な複合クエリ、おびただしいツールやコネクタのエコシステムを、さらに巨大なビッグデータアプリで最終的に利用できるようにするための第一歩であると考えられます。私はPostgreSQL上で動作する新しい時系列データベースの開発者として、PostgreSQLが追い求める方向性に深い感動を覚えます。
ここではっきりさせておきますが、一般的なパーティショニングは何もPostgreSQL 10が最初ではありません。多くのユーザーはテーブル継承を長年PostgreSQLテーブルのスケーリングに用いています。宣言的パーティショニングとは、そこに追加された興味深いオプションにすぎません。
本記事では、PostgreSQLのパーティショニングで用いられるこれら2つのオプションを吟味することにします。
本記事では以下に重点を置きます。
- PostgreSQLが自然にスケーリングしない理由(データのパーティショニングから始める必要がある理由)
- テーブル継承によるパーティショニングのしくみ(PostgreSQL 10の主要なオプション)
- PostgreSQL 10の宣言的パーティショニングのしくみ
- 新しい宣言的パーティショニングの制限事項
私たちは、さまざまな分野の専門知識を兼ね備えた開発者がPostgreSQLに集結するという経験を得られたので、本記事では基本的な事項についていくつか解説したうえで、そうした詳細部分についても追うことにします。もちろん、最初のセクションから先の部分については皆さまの専門性のレベルに応じて適宜読み飛ばしていただいて結構です。
メモ
宣言的パーティショニングは、PostgreSQLパーティショニングの新しい進路の第一歩に過ぎません。これを基礎として、この先さらに改良が重ねられる予定です。しかし本記事では、そうした輝かしい将来計画の方ではなく、あくまでPostgreSQL 10の現状についてのみ考察いたします。
PostgreSQLだけでは自然なスケールがうまくいかない理由
これは、RAMとディスクの間のパフォーマンスの違いに由来します。
多くのリレーショナルデータベースでは、データのサイズ固定ページの(順序のない)コレクションに1つのテーブルを保存し(例: PostgreSQLのページサイズは8 KB)、システムはそれらの上にデータをインデックス化するためのデータ構造(ヒープなど)を構築します。インデックスを使うことで、指定されたID(例: 銀行の口座番号)を持つ行をクエリで素早く検索できます。これにより、そのためにテーブル全体を何らかのソート順に基いて片っ端からスキャンする必要がなくなります。
しかし、インデックスに使うすべての(ほぼ固定サイズの)ページがメモリ上に収まりきれなくなるほどの大規模データになると、ツリーのさまざまな部分をランダムに更新するときに(ページをディスクからメモリに読み込み、メモリ上で変更し、他のページの場所を空けるためにディスクに書き戻す)ディスクI/Oが著しく増加します。さらに、PostgreSQLのようなリレーショナルデータベースは、インデックスの値を効率よく検索するために、各デーブルで用いるインデックス(やB-treeなど)を保持し続けます。すなわち、インデックスを付けるカラム数が増えるに連れて、問題が複合的に発生します。
PostgreSQLにおけるメモリのスワップイン/スワップアウトのコストについては、以下のパフォーマンスグラフでご覧いただけます。テーブルサイズの増加に伴ってINSERTのスループットが分散しつつ急落しています。これは、リクエストがメモリでヒットするか、ディスクからのフェッチ(複数の可能性あり)を要するかによって変わります。
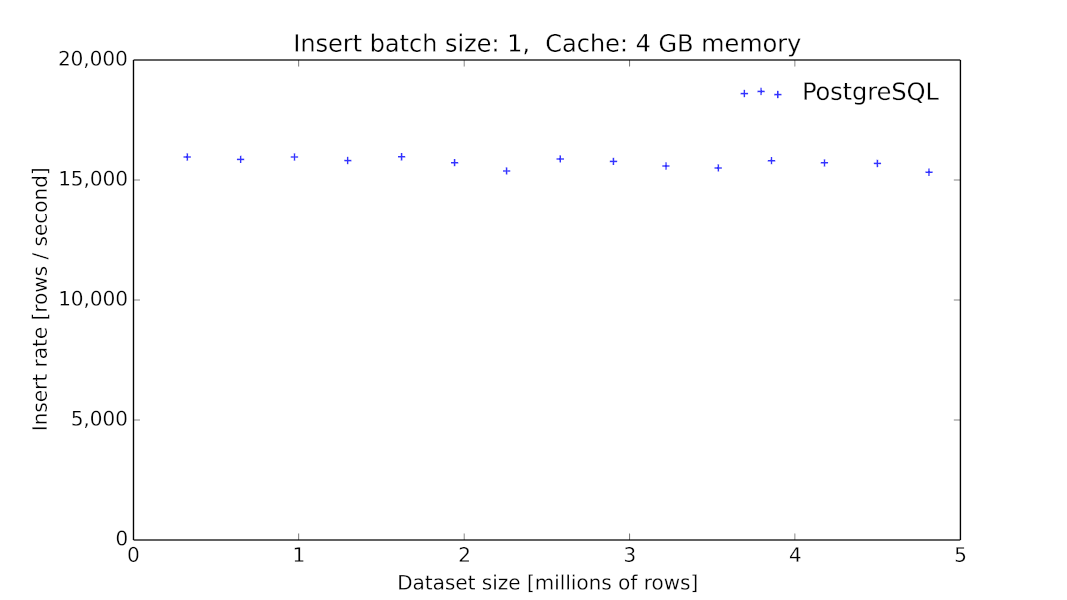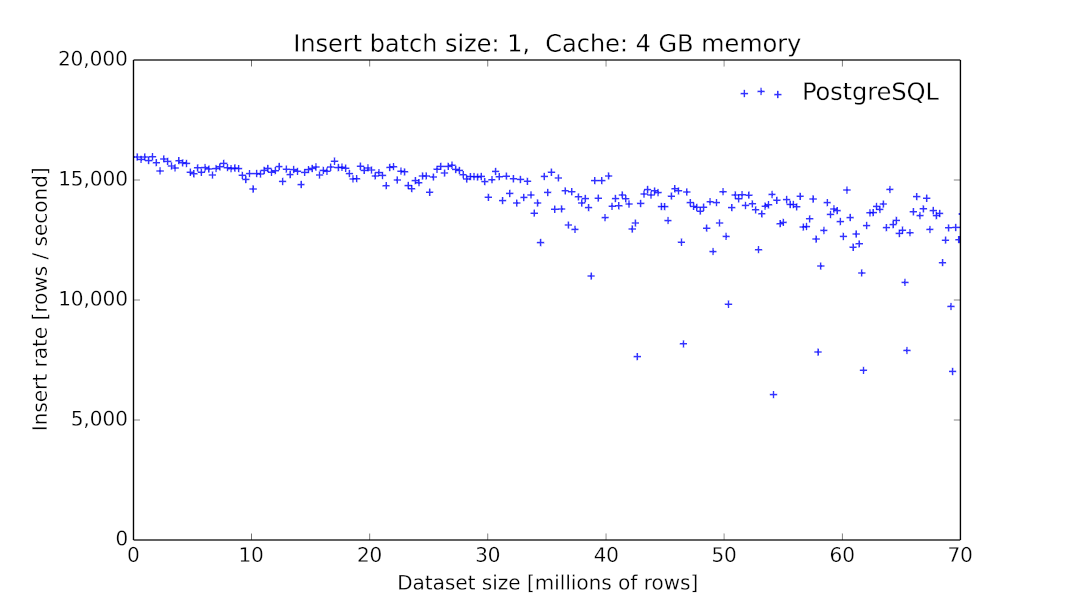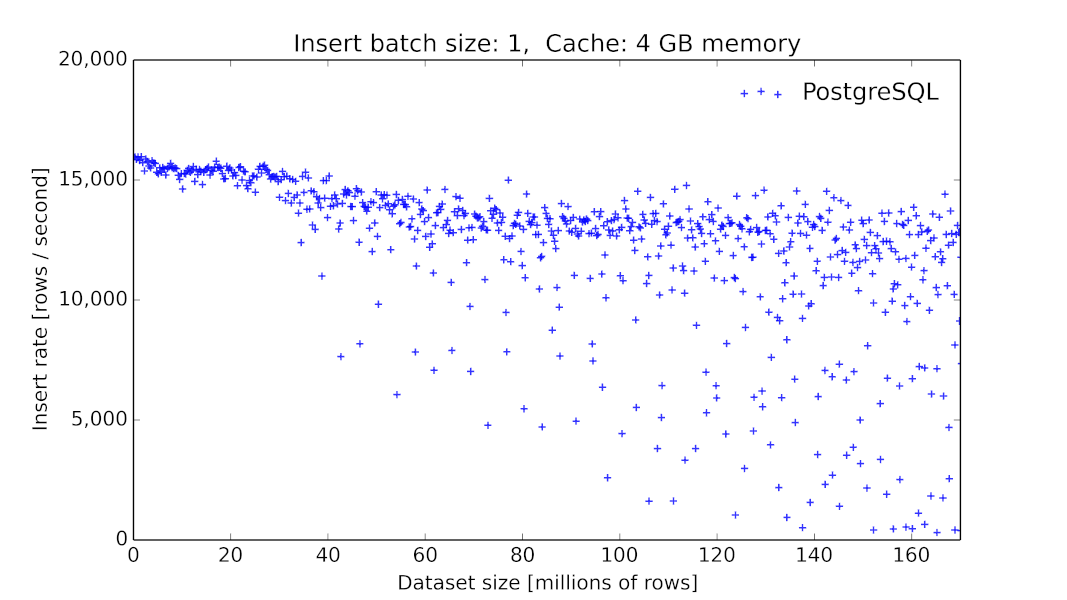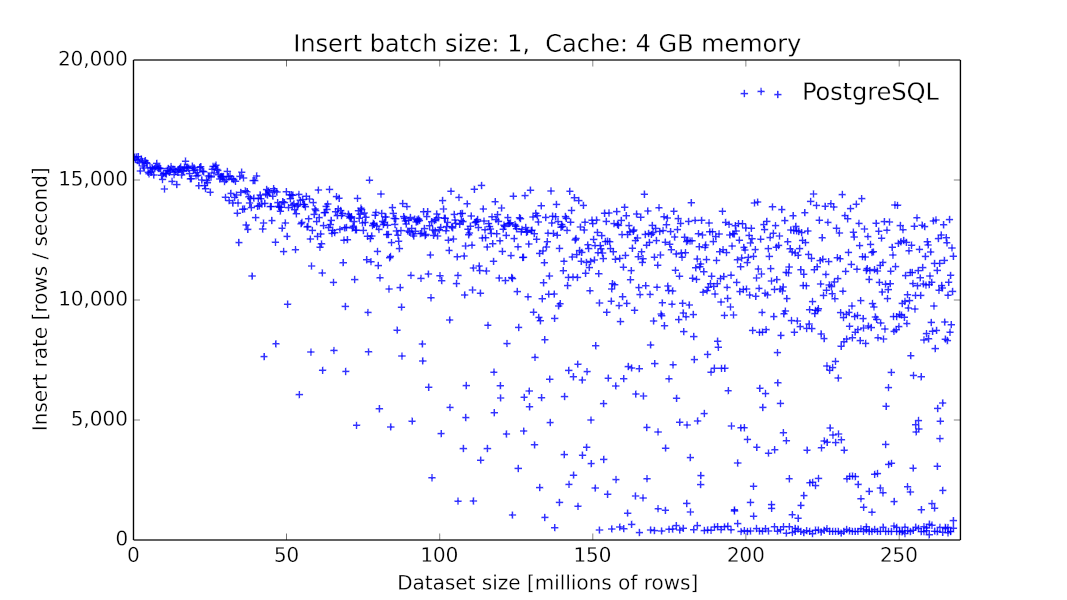
PostgreSQL 9.6.2(Azure標準DS4 v2(8コア)マシン+DDSベースのプレミアムLRSストレージ環境)におけるテーブルサイズの関数としてのINSERTのスループットです。クライアントは個別の行をデータベースにINSERTします(それぞれにタイムスタンプ、ランダムに選択されるインデックス付きID、追加の数値測定10件: 計12個のカラムを含む)。PostgreSQLの測定結果は当初15000件(INSERT/秒)ですが、5千万行を超えると著しく低下し、分散の度合いも極めて大きくなります(中にはINSERT/秒が100件台のものまであります)。
(あるベンチマークでは素のPostgreSQLでのINSERTのパフォーマンスは10億行にも達します。1万行のバッチINSERTの結果についてはこちらでご覧いただけます)
パーティショニングというソリューション
テーブルのパーティショニングは、ディスクへのスワップの高コスト問題を回避するうえで有用です。巨大なテーブルをパーティションに分割することで得られるサブテーブルのインデックスはINSERT中もメモリに保持されます(正しくインデックス化されていればの話です)。
これにより、以下を含む多くのメリットを得られます。
- すべてのインデックスがメモリに乗るようになり、INSERTやクエリが改善される
- 制約による除外が利用できるようになり、クエリが改善される
- より小さなデータセットを(パーティションごとに)配置することで、シーケンシャルスキャンを効率よくデータベースで利用できることがある
- インデックスのサイズが小さくなるため、
VACUUMやREINDEXなどのメンテナンス操作が高速化される - 全パーティションの削除が著しく高速化される(
DROP TABLEだけで行え、高コストのVACUUM操作を回避できるため)
巨大なテーブルの代わりにパーティショニングを検討すべき正確なポイントは、負荷やマシンリソースによって異なります。たとえば上述のグラフでは、表記の負荷およびマシンスペックにおけるPostgreSQLのパフォーマンスが5千万行を超えたところで低下しています。メモリを追加すれば、この問題の発生ポイントを押し上げられます。一般に、PostgreSQLテーブルに巨大なデータを書き込むのであれば、いずれどこかでパーティショニングは必要になります。
テーブル継承によるパーティショニング
PostgreSQL 10登場前のテーブルパーティショニングは、テーブル継承という形でのみ実行可能でした。テーブル継承はPostgreSQL 10以後も、宣言的パーティショニングでは力不足な状況において有用なパーティショニングオプションのひとつです。
テーブル継承を用いてパーティショニングするには、まず親テーブルを1つ作成してから子テーブルをパーティションごとに作成します。これはCREATE TABLEステートメントでINHERITS句を用いて行います(継承リンクが作成されます)。親テーブルにクエリをかけると、親テーブルと子テーブル群の両方からデータが返されます。
具体的には、テーブル継承を実装するために以下の操作が必要です。
- 親テーブルを作成する(すべてのパーティションはこれを継承する)。
- 子テーブルを複数作成する(各子テーブルはデータのパーティション1つを表し、親テーブルを継承する)。
- パーティションテーブルに制約を追加することで、パーティションごとの行の値を定義する。
- 親テーブルや子テーブルのインデックスを個別に作成する(インデックスは親テーブルから子テーブルに展開されない)。
- マスターテーブルに最適なトリガ関数を1つ作成して、親テーブルへのINSERTを適切なパーティションテーブルに振り分ける。
- このトリガ関数を呼び出すトリガを1つ作成する。
- 子テーブルのセットが変更される場合は、必ずトリガ関数を再定義すること。
テーブル継承は長年の間、開発者がPostgreSQLの扱いにくいテーブルをパーティショニングするための有用な手段でありつづけました。テーブル継承が提供する柔軟性も便利です。たとえば、親テーブルに現在ないカラムを子テーブルが余分に持つことを許可して、ユーザーの指定に沿った形でデータを分割できます。
しかし、上述の手順からわかるように、テーブル継承では手動の操作の手間がかなり増えてしまいます。一部の手順についてはスクリプトで自動化できますが、それでもエンジニアがつきっきりで作業しなければならず、オーバーヘッドが増大します。
テーブル継承にはいくつかの制限事項もあります
- データの一貫性は、子テーブルごとに指定する
CHECK制約に依存します。 INSERTコマンドやCOPYコマンドを行っても、データは継承階層内の他の小テーブルに自動では反映されませんが、かといってトリガに頼ると今度はINSERTが遅くなります。- 子テーブルの作成と維持には、本質的に手動の作業が欠かせません。
- 3に関連しますが、パーティショニングの再編成作業はかなりの手間です(ディスクの追加やスキーマ変更など)。
- パーティション化されたテーブル全体に渡る一意性の確保はサポートされていません。
- 子テーブルには、インデックスや制約といったさまざまなメンテナンス用コマンドを明示的に適用する必要があり、管理タスクが著しく複雑になります。
宣言的パーティショニングは、こうした制限事項や手動操作を克服するためにPostgreSQL 10に導入されました。
PostgreSQL 10の宣言的パーティショニングは、上述の問題1と2を解決します。3の問題についても単純化されますが、それでも結構な量の手動操作や制限事項がつきまといます。
PostgreSQL 10の宣言的パーティショニング
宣言的なテーブルパーティショニングは、PostgreSQLのデータをパーティショニングときに必要な作業量を削減します。これは、パーティション化テーブルや子テーブルパーティションの作成構文を改良することで達成されました。
現時点の宣言的パーティショニングではRANGEパーティションとLISTパーティションがサポートされています。
RANGE: テーブルを、キーカラムやカラムセットで定義される「範囲」にパーティショニングします。異なるパーティションに振り分けられた値(device_idなど)は重複しません。LIST: テーブルを、各パーティションにキーのどの値があるかというリストを明示することでパーティショニングします。適用対象は単一のカラム(device_typeなど)のみとなります。
宣言的パーティショニングのしくみ
最初にパーティションテーブルを1つ作成します。
PARTITION BY句を用いてパーティション化テーブルを1つ作成します。これに含まれるパーティショニング手法(この例ではRANGE)やカラムのリストはパーティションのキーとして使われます(例はPostgreSQL 10ドキュメントをそのまま引用しました)。
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
- パーティション化テーブルを作成すると、次のようにパーティションを手動で作成できます。
CREATE TABLE measurement_y2006m02 PARTITION OF measurement
FOR VALUES FROM ('2006--02--01') TO ('2006--03--01')
CREATE TABLE measurement_y2006m03 PARTITION OF measurement
FOR VALUES FROM ('2006--03--01') TO ('2006--04--01')
CREATE TABLE measurement_y2006m04 PARTITION OF measurement
FOR VALUES FROM ('2006--04--01') TO ('2006--05--01')
...
CREATE TABLE measurement_y2007m11 PARTITION OF measurement
FOR VALUES FROM ('2007--11--01') TO ('2007--12--01')
- 続いてインデックスを作成できます。
CREATE INDEX ON measurement_y2006m02 (logdate);
CREATE INDEX ON measurement_y2006m03 (logdate);
CREATE INDEX ON measurement_y2006m04 (logdate);
...
CREATE INDEX ON measurement_y2007m11 (logdate);
パーティション化テーブルの動作は、テーブル継承の親(マスター)テーブルと似ていますが、大きく改良されていて、背後にある子テーブルのパーティションに対してはるかに強力なクエリインターフェイスを提供します。たとえば、TRUNCATEやCOPYといったコマンドをパーティション化テーブル経由で子テーブルに対して実行できます。さらに、パーティション化テーブルを経由してデータを背後の子テーブルにINSERTできます。これが可能なのはINSERT時にタプル(行など)が正しいパーティションにルーティングされるためで、テーブル継承のときのようにトリガに頼る必要がありません。
以上のように、テーブル継承の8つの手順は宣言的パーティショニングで劇的にシンプルになります。3つの手順で手動操作が削減され、ユーザーにとってわかりやすいものになりました。INSERTの自動化や、パーティション化テーブル経由でのテーブルコマンドの追加反映も大きな成果です。
宣言的パーティショニングは、PostgreSQLの新しいパーティショニングの第一歩に過ぎません。私たちが理解した限りにおいてですが、テーブル継承と対照的に、パーティショニングへの追加制約(親テーブル自身はデータを保持してはならないなど)が宣言的パーティショニングに導入されたことで、さらに強力なクエリ最適化などの機能を今後PostgreSQLで構築する準備が整いました。言い換えれば、PostgreSQL 10の宣言的パーティショニングのほとんどの改良点はパーティション定義のインターフェイスや構文に集中していますが、今後はこの構造を用いてさらに高度な機能や最適化を実装できるようになるはずです。
宣言的パーティショニングの制限事項
宣言的パーティショニングは、PostgreSQLのパーティショニングの自動化を進めるうえで重要な一歩を踏み出していることは間違いありません。しかしながら、まだ制限事項がいくつもあります。
手動によるパーティション管理
パーティション管理作業は宣言的パーティショニングによって楽になりましたが、それでも必要な手動操作がかなり残っています。
たとえば、データの子テーブルは、データがINSERTされる前に存在している必要があります。データが成長・進化していると、これが管理上の困難になるかもしれません。たとえば時期を基準にパーティショニングする場合、新しいデータがやってきたときにシステムが自動で新しいパーティションを新規作成してくれると便利です。現時点ではデータベース管理者が手動で操作しなければなりません。さらに、使いもしないパーティションを事前に多数作成するとパフォーマンスに悪影響が生じる可能性もあります。
手動操作が必須となる制限事項はドキュメントの「5.10.2.3 制限事項」にも掲載されており、以下のような記述があります(訳注: 訳文はリンク先から引用し、原文に合わせて調整しました)。
- すべてのパーティションに適合するインデックスを自動的に作成する機能はありません。 インデックスは個々のパーティションについて別々のコマンドで追加しなければなりません。
- 行をあるパーティションから別のパーティションに移動させることになるUPDATEは失敗します。
- 行トリガーが必要であれば、個々のパーティションに定義されなければなりません。
こうした制限事項から、テーブル作成時には現在もテーブル空間(tablespace)の割り当てやインデックス・制約の作成は適宜手動で行う必要があることが見て取れます。同様に、親テーブルを変更する場合は、個別のパーティションにも手動でインデックスや制約の変更をかける必要があります。さらに、CLUSTERやREINDEXといった多くのコマンドを個別の子テーブルに適用する必要もあります。
まとめると、PostgreSQL 10における個別のパーティション管理は、パーティションテーブルのインターフェイス経由ですべて賄えるわけではありません。追加操作が必要とされているため、特にパーティションを後から繰り返し追加したときやデータモデルに変更が生じたときに、データ管理上のボトルネックが形成されてしまう可能性があります。
多次元パーティショニングはつらいよ
スケーラビリティやクエリのさらなる改良のために重要となる「多次元パーティショニング」では、既存パーティション上に最初のパーティションが作成された後に手動でサブパーティションを作成しなければなりません。例として、LIST(デバイスなど)というディメンジョンがひとつ、RANGE(期間など)というディメンジョンがひとつあるとすると、これらをパーティショニングするには、最初にすべてのLISTパーティションを作成してから、それぞれの子テーブルでそれに対応するRANGEサブパーティションを作成する必要があります(逆も同様)。これによってテーブルのツリー階層が形成され、端点(leaf)のサブパーティションが効率よくタプルを保持します。
-- 「デバイス」パーティションの作成
CREATE TABLE conditions_p1 PARTITION OF conditions
FOR VALUES FROM (MINVALUE) TO ('g')
PARTITION BY RANGE (time);
CREATE TABLE conditions_p2 PARTITION OF conditions
FOR VALUES FROM ('g') TO ('n')
PARTITION BY RANGE (time);
CREATE TABLE conditions_p3 PARTITION OF conditions
FOR VALUES FROM ('n') TO ('t')
PARTITION BY RANGE (time);
CREATE TABLE conditions_p4 PARTITION OF conditions
FOR VALUES FROM ('t') TO (MAXVALUE)
PARTITION BY RANGE (time);
-- 「期間」パーティションの作成(デバイスパーティションごとに1週間を割り当てる)
Create time partitions for the first week in each device partition
CREATE TABLE conditions_p1_y2017m10w01 PARTITION OF conditions_p1
FOR VALUES FROM ('2017-10-01') TO ('2017-10-07');
CREATE TABLE conditions_p2_y2017m10w01 PARTITION OF conditions_p2
FOR VALUES FROM ('2017-10-01') TO ('2017-10-07');
CREATE TABLE conditions_p3_y2017m10w01 PARTITION OF conditions_p3
FOR VALUES FROM ('2017-10-01') TO ('2017-10-07');
CREATE TABLE conditions_p4_y2017m10w01 PARTITION OF conditions_p4
FOR VALUES FROM ('2017-10-01') TO ('2017-10-07');
-- 各端点のパーティションに期間〜デバイスのインデックスを作成
CREATE INDEX ON conditions_p1_y2017m10w01 (time);
CREATE INDEX ON conditions_p2_y2017m10w01 (time);
CREATE INDEX ON conditions_p3_y2017m10w01 (time);
CREATE INDEX ON conditions_p4_y2017m10w01 (time);
INSERT INTO conditions VALUES ('2017-10-03 10:23:54+01', 73.4, 40.7, 'sensor3');
複数に渡る手順による処理と、追加のディメンジョンやパーティションのサブレベルがあることでさらに複雑化が進むため、使いもしない巨大な継承ツリーを作ると、INSERTやクエリの両方で処理する必要のあるテーブル数が増加し、パフォーマンスやスケーラビリティに悪影響が生じる可能性があります。
データ統合でサポートされていない機能
ドキュメントの「5.10.2.3 制限事項」に記載されているように、PostgreSQLで使われているデータ統合(data integrity)機能の中には、PostgreSQL 10でサポートされていないものがあります。
- パーティション上に主キーを作成できません。つまり、パーティション化テーブルを参照する外部キーも、パーティション化テーブルから別のテーブルを参照する外部キーも、サポート対象外です。
- 1つのパーティション化テーブル全体に渡る一意制約(排他制約)はサポートされません。一意制約や排他制約は、個別のパーティション上にのみ作成できます。このため、
ON CONFLICT句もサポート対象外となります(ただしPostgreSQL 11の機能候補にはあるようです)。
IoTアプリや時系列アプリの多くがON CONFLICT句によるupsert(訳注: update+insert)を利用しているのを目にしますので、そうした分野のアプリではかなりハードルが高くなるかもしれません。主キーが使えない点も、主キーの存在を前提とするORMユーザーにとって問題になるかもしれません。
最後に
宣言的パーティショニングは、PostgreSQLの巨大データセットでのスケーリングを推進するうえで重要な一歩です。PostgreSQL 10では、よりシンプルなパーティション定義構文が導入され、タプルもルーティングできるようになりました。どちらもパーティショニング設定を簡単にしてくれるものであり、さまざまな場面で恩恵を得られます。しかし私たちからすれば、現在進行中の作業の中で最もエキサイティングなのは、まだ登場していない「クエリ最適化」です(PostgreSQL 11以降の機能候補に挙がっています)。管理方法や使い勝手の改善の余地も、まだまだたっぷり残されています。
しかし、PostgreSQLのコア開発とは別立てで、(PostgreSQLの拡張性の高さのおかげで)TimescaleDBなどの拡張を用いてパーティションの管理や使い勝手を大きく改良することもできます。
PostgreSQLはこれらの拡張によって、指数関数的に増加する現実世界の時系列データのような、従来のOLTP(オンライントランザクション処理)の範疇を超える多様な負荷を支えることができます。
時系列データをPostgreSQL 10の宣言的パーティショニングで動かすしくみ(および私たちのパーティショニング手法が他とどう異なっているか)について知りたい方は、ぜひ最近の私たちの記事『Problems with PostgreSQL 10 for time-series data』をご覧ください。
本記事を気に入っていただけましたら、ぜひ元記事へコメントお願いします。
TimescaleDBについて詳しくお知りになりたい方は、GitHubのtimescale/timescaledbをご覧いただき(★追加はいつでも大歓迎です😃)、メールにてお問い合わせください。