更新履歴
- 2018/10/11: 初版公開
- 2020/11/12: 追記・更新
- 1: 基本となる8つの正規表現(本記事)
- 2: 正規表現とは何か/ワイルドカードとの違い
- 3: 冒頭/末尾にマッチするメタ文字とセキュリティ、文字セットの否定と範囲
- 4: 先読みと後読みを極める
- 5(特別編)
|と部分マッチのワナ - 6: 文字セットのショートハンド
- 7: Unicode文字ポイントとUnicode文字クラス
- 8: 対象の構造を意識した「適度にDRYな」書き方
- 9:
.*や.+がバックトラックで不利な理由 - 10: 危険な「Catastrophic Backtracking」前編
こんにちは、hachi8833です。
BPS社内勉強会で発表したスライドを元に、正規表現を学ぶときに最初に押さえておきたい基本的なポイントを入門用にまとめました。説明では主にRubyの正規表現を使っていますが、特定の正規表現ライブラリになるべく依存しない汎用的な記述を心がけています。
正規表現に関する専門書籍やWebサイトはいろいろありますが、正規表現には唯一の正解がなく、さまざまな書き方が可能です。しかもそうした資料では機能の説明がびっしり網羅されていて、忙しい人にとって「どれが重要か」「どれが要注意か」を短時間で汲み取ることが難しくなっています。
そもそも、正規表現の書き方を単独のカリキュラムとして扱っている大学やプログラミング教室が私の知る限りでは見当たらず(学問としての正規表現はこの限りではないと思いますが)、正規表現をまとめて学ぶ機会が皆無です。
ググって目についたメタ文字を手当たり次第に使っていると、効率の悪い書き方をしてしまったり、書き方を見つけられなかったり、見つけにくいバグを埋め込んでしまったりすることがしばしばあります。
しかも困ったことに、ネット上に落ちている正規表現の解説や例にしばしば質の低いものがあります(日本語・英語を問わず)。拾い食いには要注意です。
私も質の低い情報を垂れ流さないよう気をつけないといけませんね💦。お気づきの点がありましたら@hachi8833までお願いします。
通常ならば「正規表現とは何か」から説明するところですが、第1回ではあえて正規表現のメタキャラクタ(メタ文字)を基本的かつ有用な順に並べ、順に学ぶことで自然とベストプラクティスを実現できるようにしてみました。正規表現そのものについては次回の#2で解説し、#3以降で順次高度な機能に進みます。
第1回は以下の8つのメタ文字に絞りました(メタ文字をクリックするとジャンプできます)。少なくともこれらはどの正規表現環境(ライブラリ)でも利用できます。
?- ・直前の1文字が0個または1個であることを表すメタ文字
・最短一致 +- ・直前の1文字が「1個以上」繰り返されることを表すメタ文字
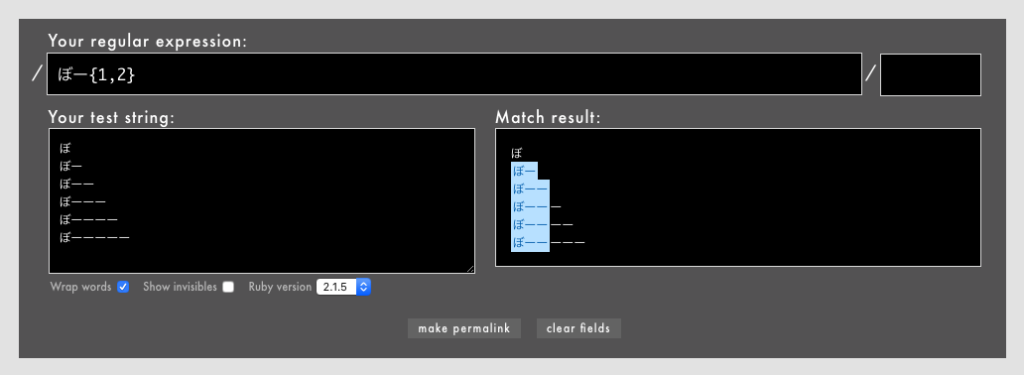
{}- ・直前の文字の繰り返し回数を指定するメタ文字
\- ・直後のメタ文字を通常の文字として扱う(エスケープ文字)
.- ・任意の1文字を表すメタ文字(ただし改行文字は除く)
[]- ・この記号で囲まれた文字(文字セット)のどれか1文字を表すメタ文字
()- ・文字列をグループ化するメタ文字
|- ・複数のパターンを列挙するメタ文字
- 特に言及しない限り、対象文字列のエンコードはNFCで正規化済みのUTF-8とします。
- サンプルの正規表現はRuby風に/
/で囲みます(囲みの/ /は正規表現そのものには含めませんのでご注意ください)。また、正規表現の断片は//で囲みません。
⚓参考: 正規表現をインタラクティブに試せるサイト
正規表現をインタラクティブに試すのに便利なWebサイトがいくつかありますので、こうしたサイトで正規表現を試しながら読み進めることをおすすめします。本シリーズでは原則としてrubular.comを使います。
- Ruby向け: rubular.com --
ただしRuby 2.1.5相当その後Ruby 2.5.9にアップデートされていました😂
- Perl/PHP/Python/Go言語向け: regex101.com
- .NET Framework向け: regexstorm.net
なお、こういったサイトに限りませんが、顧客データや個人情報などを流し込まないよう注意しましょう。
⚓ 正規表現はじめの一歩: ?
?- 直前の1文字が0個または1個であることを表すメタ文字
?は単純ですが、実はこれだけでも相当使いでがあります。私は心の中でこっそり「ありやなしやの?」と呼んでいます。
ご注意いただきたいのは、?は何かの文字の代用ではなく、「?の直前の文字を修飾している」ことです。いわゆるワイルドカードの?とは機能が異なります(ワイルドカードとの違いについては#2で別途解説します)。
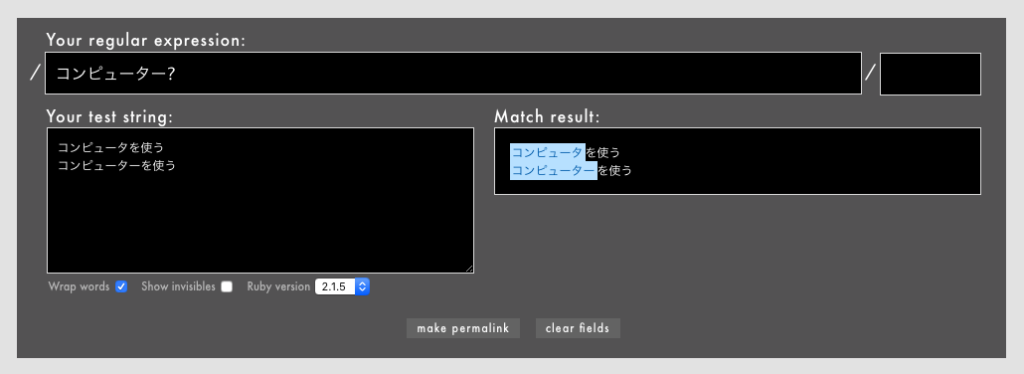
?の典型的な使い方は、カタカナの長音「ー」がある場合とない場合の両方にマッチさせたいときです。
- 例: /
コンピューター?/とすると、「コンピューター」と「コンピュータ」のどちらにもマッチします(Rubular)。
なお、マッチさせるだけなら/
コンピュータ/とすれば「コンピューター」にも「コンピュータ」にもマッチします。ハイライトするとか置き換えるなどの際には/コンピューター?/とする必要があります。
なお、?のもうひとつの機能については「最短一致」で解説します。
⚓ 正規表現はじめの二歩: +
+- 直前の1文字が「1個以上」繰り返されることを表すメタ文字
+も有用性の高いメタ文字です。「1個以上」なので、指定の文字がいくつ連続していてもマッチします。これも直前の文字を修飾しています。
なお、先ほどの?やこの+は、難しく言うと「量指定子(quantifier: 量化子とも)」に分類されます。要するに、直前の文字がいくつあるかを指定するものです。
- 例: /
ずうー+っと/というパターン(Rubular)。
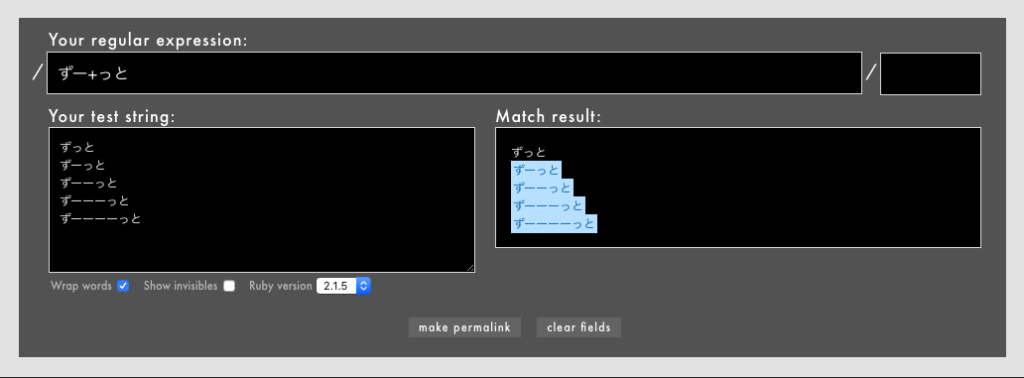
これは「ずうーっと」「ずうーーっと」「ずうーーーっと」...などにマッチしますが、長音のない「ずうっと」にはマッチしません
+は有用ですが利用にはいくつかの注意が必要です。この後で+の注意点について説明します。
⚓ 正規表現はじめの三歩: { }
{N}- 直前の1文字をN回繰り返すことを表す(Rubular)
{N,}- 直前の1文字をN回以上繰り返すことを表す(Rubular)
{N, M}- 直前の1文字をN回以上M回以下繰り返すことを表す(Rubular)
{ }も量指定子の一種で、回数を数値で指定できるのが特徴です。通常の文字はもちろん、文字セット[]や()などを修飾して回数を指定することもできます。
{ }も有用な表現です。+だとマッチの個数に上限がありませんが、{ }だと上限を指定できるので効率が落ちにくく、+よりも安心感があるので、回数を限定できるのであれば+よりも{}を積極的に使いましょう。
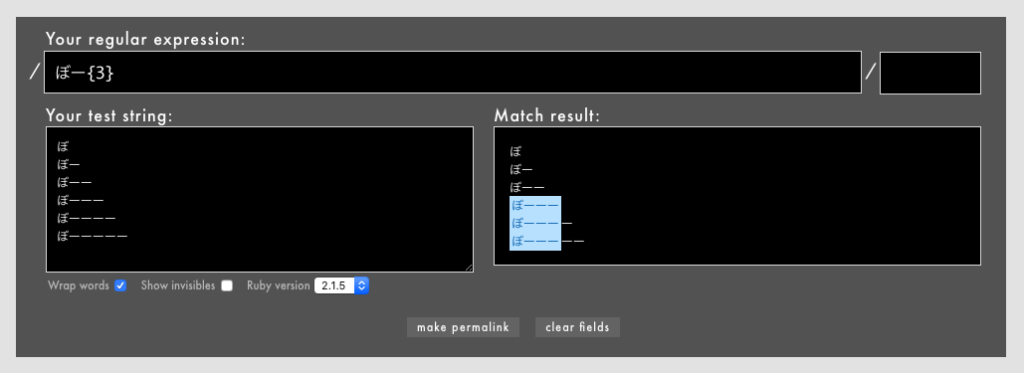
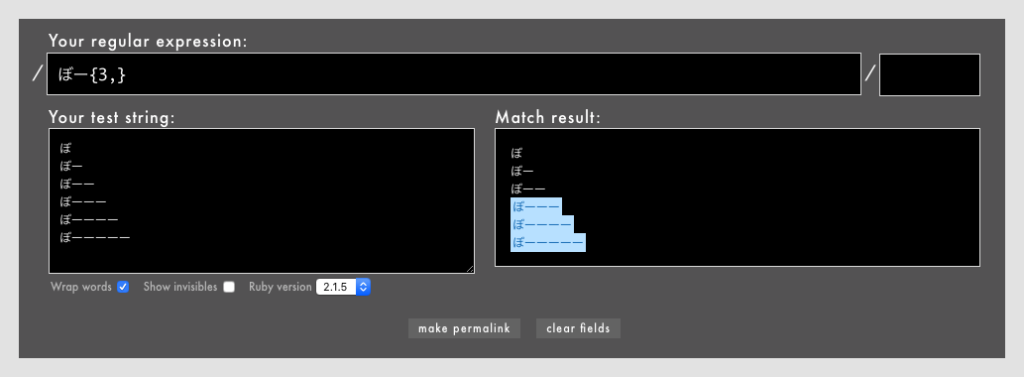
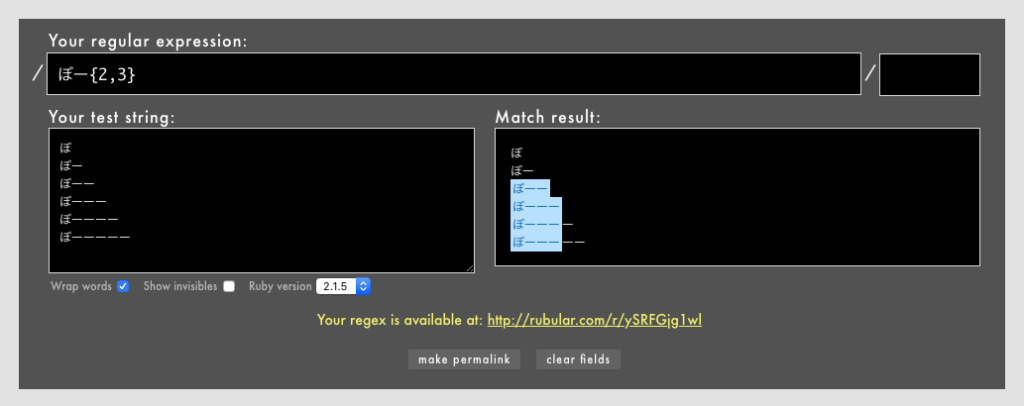
なお、上の例には「N回以下」がありませんが、{,N}という表現は私が知る限りではなぜかRubyでしか使えません。
しかし{N, M}のパターンを応用して{1, 6}や{0, 2}のように開始を1やゼロにすれば「N回以下」を表現できるので実用上は問題ありません(Rubular)。
⚓ 正規表現はじめの四歩: \
\- 直後のメタ文字を通常の文字として扱う(エスケープ)
\はバックスラッシュと呼ばれ、正規表現ではバックスラッシュ直後のメタ文字の機能をキャンセルして通常の文字として扱うのに使われます。この操作を「エスケープ」と呼びます。なお、通常のスラッシュは/です。
バックスラッシュは、正規表現以外でもプログラミング言語などの文字のエスケープによく用いられます。
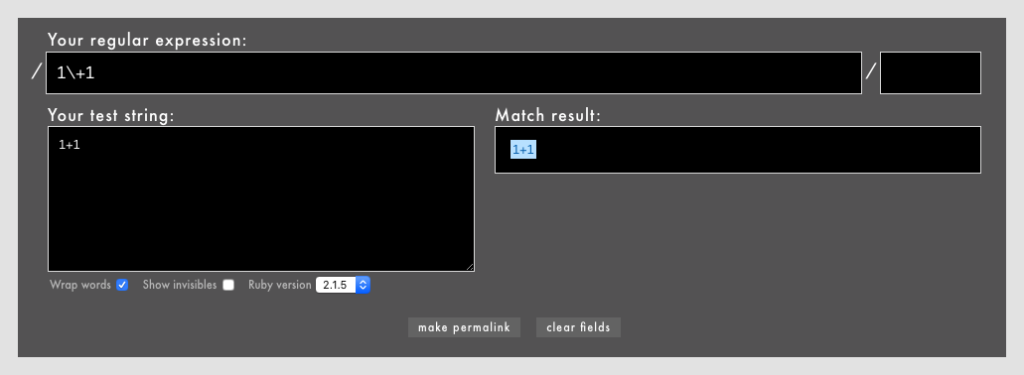
「1+1」という文字列にマッチさせたいときは、正規表現の中で\+とすると、+がメタ文字ではなく通常の+として扱われます。
- 例: /
1\+1/というパターン(Rubular)。
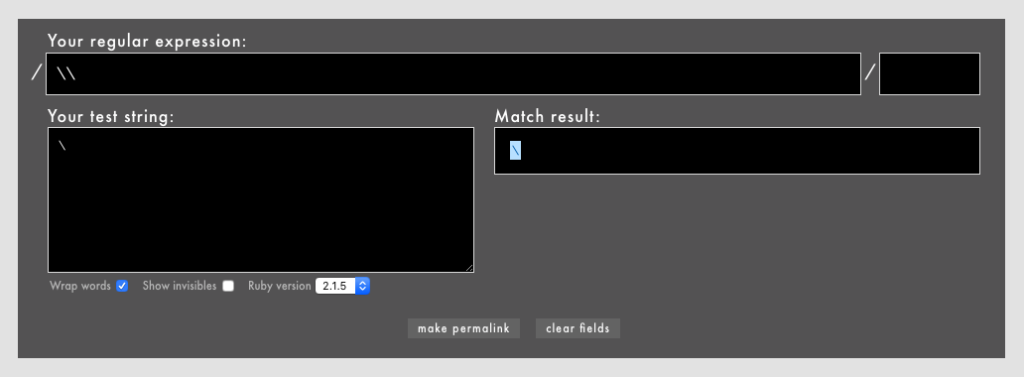
バックスラッシュ\そのものをエスケープしたい場合は、\\のように二重に表記します(Rubular)。
⚓ 正規表現はじめの五歩: .
.- 任意の1文字を表すメタ文字(ただし改行文字は除く)
.を単体で使うことは、意外にもそれほどありません。
そのかわり、さっきの+を組み合わせて.+とすることで、「1文字以上の任意の長さの文字列」を表すのに非常によく使われます。.+はぜひ覚えておきたい定番の表現です。
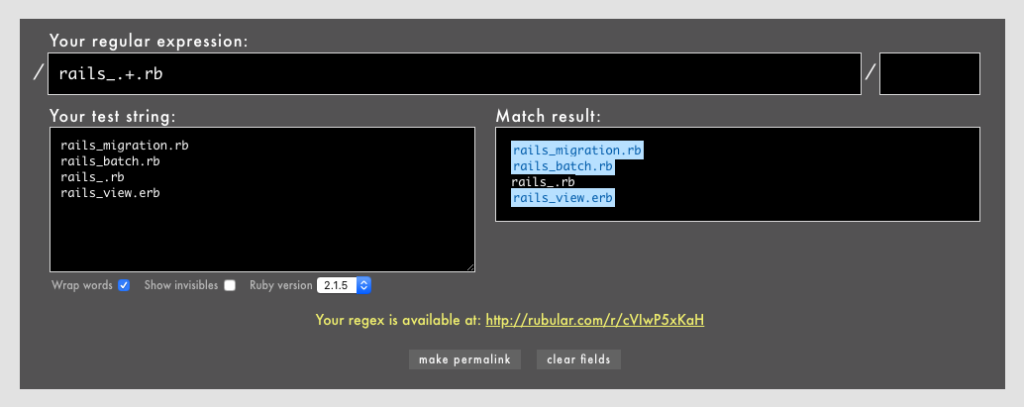
- 例: /
rails_.+\.rb/というパターン(Rubular)。
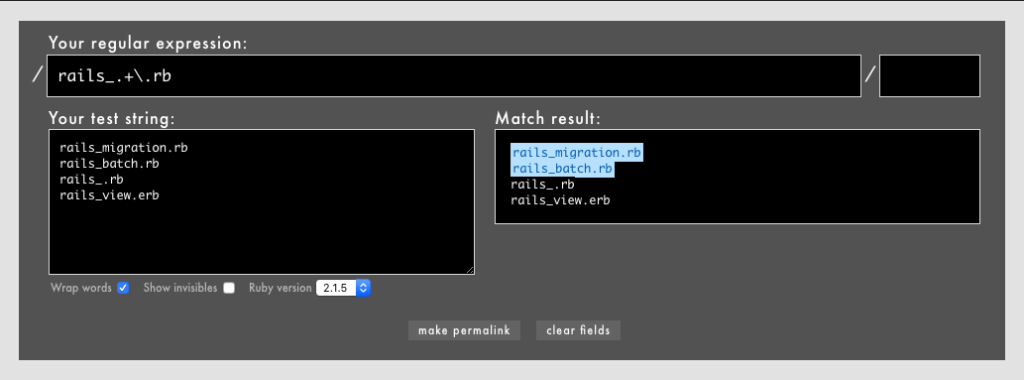
これは「rails_migration.rb」や「rails_batch.rb」など「rails_なんちゃら.rb」にマッチします。この場合、_のすぐ後ろが\.rbになっている「rails_.rb」にはマッチしません。
なお\.の部分は、任意の一文字でない「本来のピリオド文字.」を表すために先ほどのバックスラッシュ\を直前に置いてエスケープしています。こうしないと、たとえば意図しない「rails_view.erb」にもマッチしてしまいます(Rubular)。
.は、多くの正規表現ライブラリで\nや\rといった改行文字にはマッチしない点にご注意ください。自分の使う正規表現ライブラリについて、このあたりの挙動を調べておくことをおすすめします。
正規表現の外からオプションを指定することで
.を改行にマッチさせられるライブラリもありますが、本シリーズではこうした外からのオプションについては扱いません。
⚓ 注意: +量指定子は「最長一致」
+のような「n個以上の繰り返し」量指定子は、正規表現ではデフォルトで最大限の長さで一致する(最長一致)ので注意が必要です(ただし正規表現エンジンによっては異なるかもしれません)。言い換えると、行けるところまでめいいっぱいマッチします。
たとえば、「豚が豚をぶったのでぶたれた豚がぶったその豚をぶった豚」という文字列に/豚.+ぶった/という正規表現を適用すると、以下のようにほぼめいいっぱいマッチしてしまいます
- 例: /
豚.+ぶった/というパターン(Rubular)
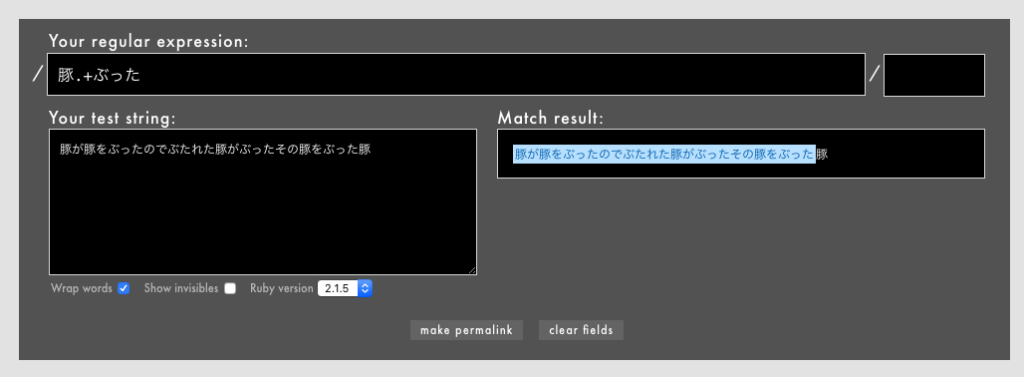
「豚をぶった」「豚がぶった」も含めて最長マッチしているので、マッチだけを調べていると気づきにくいバグになりがちです。このようにハイライトしたり置き換えようとしたときにバグが顕在化します。
⚓ ?のもうひとつの機能: 最短一致
最長一致では困る場合、多くの正規表現では量指定子(ここでは+)の直後に?を付けて+?とすることで最短一致を指定できます。この?は先ほどのありやなしやの?と意味の異なる、もうひとつの機能です。
なお、秀丸エディタでは最長一致を「欲張り一致」、最短一致を「ものぐさ一致」というユニークな言葉で表しています。英語でも「greedy match」や「lazy match」という用語が使われることがあります。
「豚が豚をぶったのでぶたれた豚がぶったその豚をぶった豚」という文字列に/豚.+?ぶった/という正規表現を適用すると、最短一致で3箇所にマッチします。
- 例: /
豚.+?ぶった/というパターン(Rubular)。
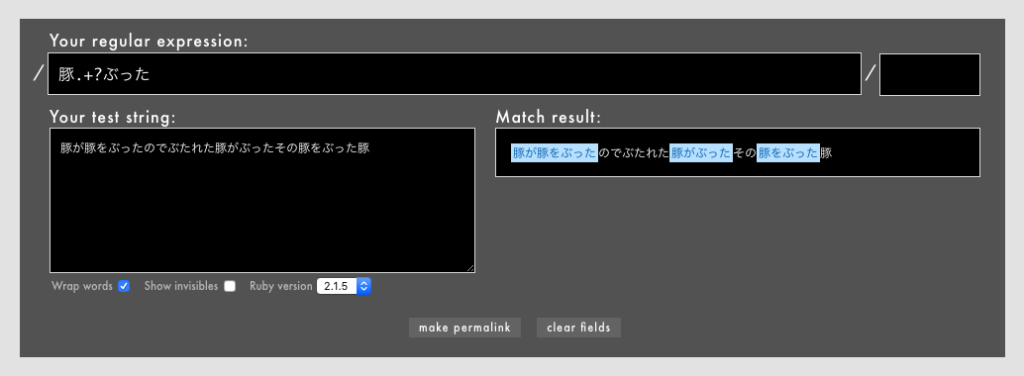
「豚が豚をぶった」「豚がぶった」「豚をぶった」の3箇所で最短マッチしています。
⚓ 注意: .+は使う前に考えよう
なお、「豚が豚をぶった」にはマッチさせたくないのであれば、.+ではなく、もっと精密な正規表現を書く必要があります。.+は有用なイディオムですが、このように意図しないマッチを呼び込む可能性があることを常に頭に置いておきましょう。
私?.+を使うことはめったにありません。基本的に.+は凶暴だと思っています。
⚓ 正規表現はじめの六歩: 文字セット[]
[]- この記号で囲まれた文字(文字セット)のどれか1文字を表すメタ文字
文字セット[]も正規表現の非常に有用なメタ文字です。後ろに量指定子を置いて[0123456789]+のように使うことがよくあります。
文字セット[]全体は1文字とみなされることにご注意ください。
「豚が豚をぶったのでぶたれた豚がぶったその豚をぶった豚」という文字列に/豚[がを]ぶった/という正規表現を適用すると、3箇所にマッチします。
- 例: /
豚[がを]ぶった/というパターン(Rubular)
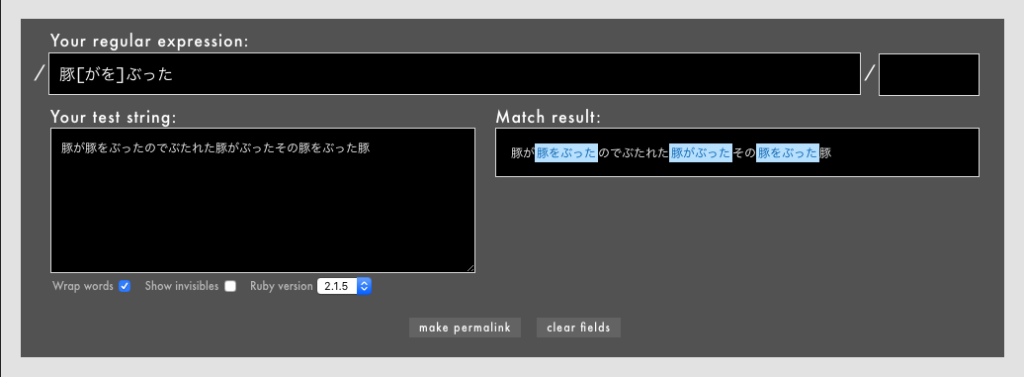
「豚をぶった」「豚がぶった」「豚をぶった」の3箇所でマッチしています。先ほどの「豚が豚をぶった」のようなマッチを排除できましたね。
文字セット[]は、数字やアルファベットに限定した文字とマッチさせるときにもよく使われます。文字セット[]の直後に+などの量指定子を置くことで、マッチの長さを任意にできます。
- 例: /
id_[0123456789]+/というパターン(Rubular)。
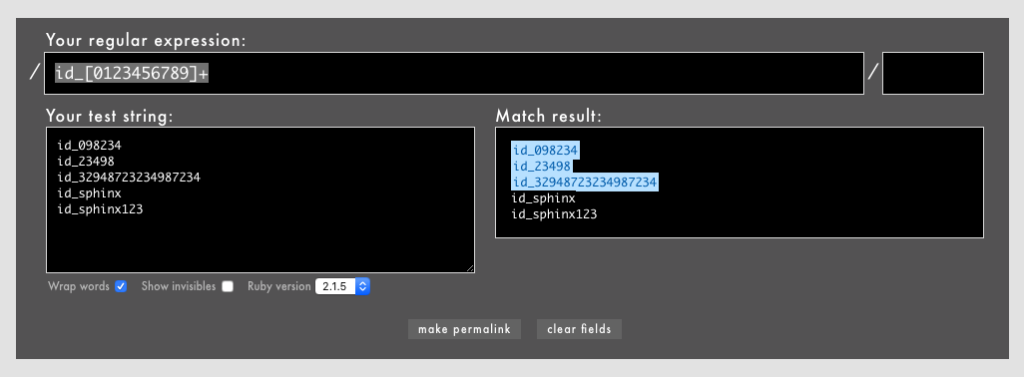
「id_」の直後に数字が1文字以上続く文字列にマッチします。
実は文字セット
[]の中は少し特殊な世界になっていますが、今後説明する予定なのでまだ気にしなくてもよいです。詳しくは正規表現: 文字クラス [ ] 内でエスケープしなくてもよい記号をご覧ください。
⚓ 文字セット[]の注意
意外に間違えられやすいのですが、文字セット[]の中に書く文字の順序はマッチに関係ありません。
- 例: /
ぐ[りら]/というパターン(Rubular)
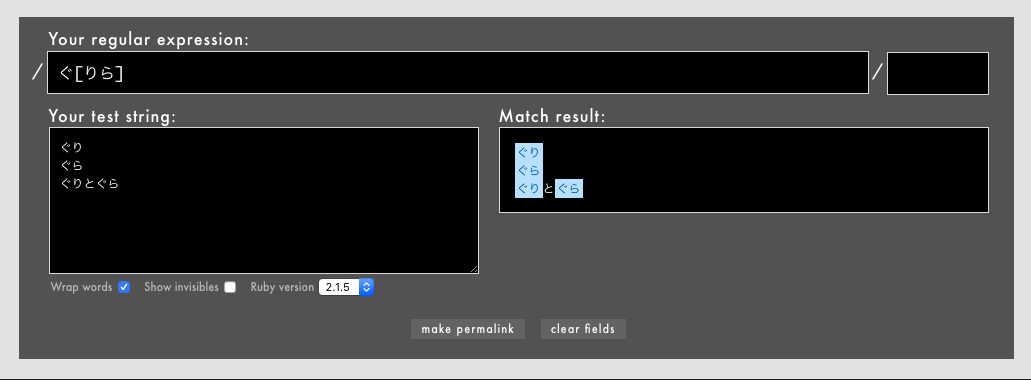
上は「ぐり」か「ぐら」にマッチしますが、これはぐ[りら]と書いても、ぐ[らり]と書いても同じです。
ただ、文字セット[ ]の中は左から順に探索されるのが普通で、1つでもマッチすればそこで探索を終えて次の文字に進みます。これを利用して、マッチする頻度の高い文字を文字セット[ ]の左の方に置くようにすると、パフォーマンス上有利になります。
⚓ 正規表現はじめの七歩: ()
()- 文字列をグループ化するメタ文字
()にはいくつかの機能がありますが、ここでご紹介するのは文字列をグループ化する機能です(他の機能は今後ご紹介します)。難しく言うと「グループ化構成体(grouping construct)」です。
先の文字セット[]では中の文字に順序がありませんが、グループ化()の場合は文字の順序が保たれます。()の直後に量指定子を置くことも、()の中でメタ文字を使うこともできます。
- 例: /
(きょ)+/というパターン(Rubular)
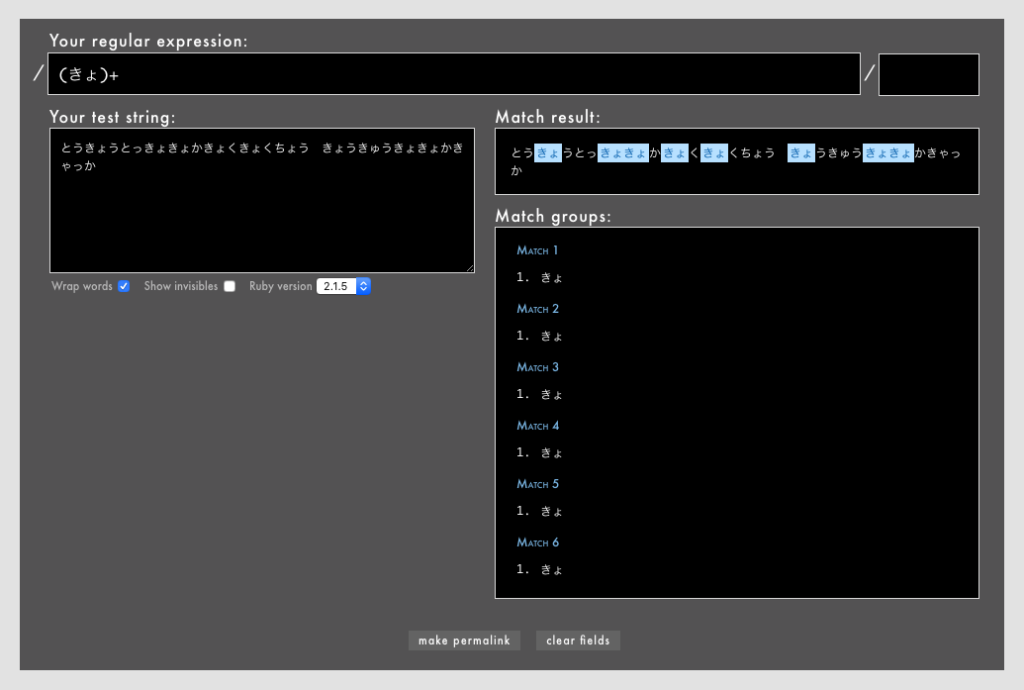
「きょ」「きょきょ」にマッチしているのがわかります。
グループ化()も単体で使うことはあまりなく、次の|とよく併用されます。
⚓ 正規表現はじめの八歩: |
|- 複数のパターンを列挙するメタ文字
|は、プログラミングにおける「OR演算(論理和)」(Rubyでは||演算子)によく似ています。難しく言うと「代替構成体(alternation construct)」です。
|は、先ほどのグループ化()と組み合わせて(dog|cat|horse|cow)のようにパターンを列挙してその中のいずれかにマッチさせるのに使うことがよくあります。この場合、「dog」「cat」「horse」「cow」のいずれかにマッチします。各文字列の長さは異なっていても構いません。
- 例: /
(東京|神奈川|鹿児島)特許事務所/というパターン(Rubular)。
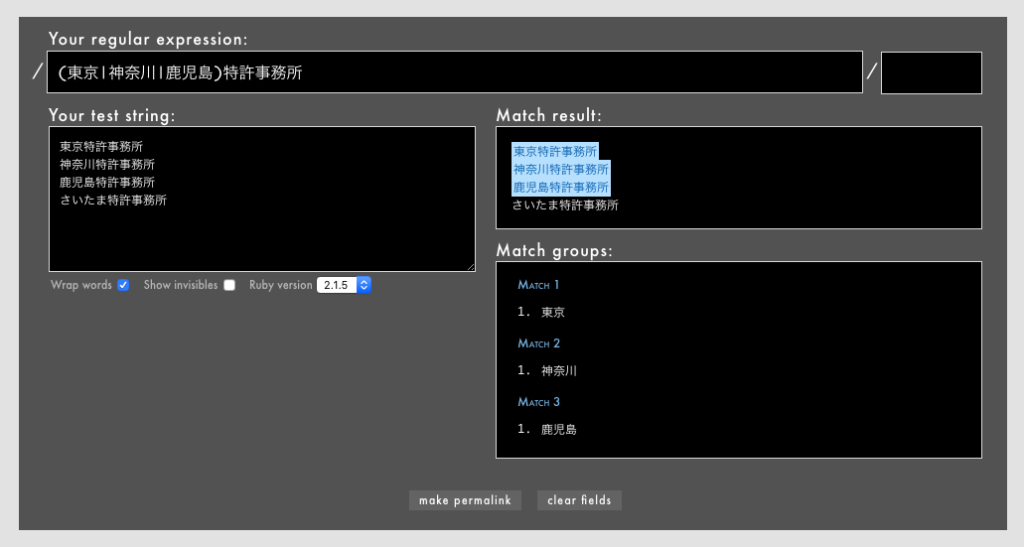
|は正規表現の中で処理の優先順位が低いのが特徴です。()に含まれない|は最後に解釈されます。
たとえば/東京|神奈川/とすると、「東京」または「神奈川」にマッチします
- 例: /
東京|神奈川/というパターン(Rubular)
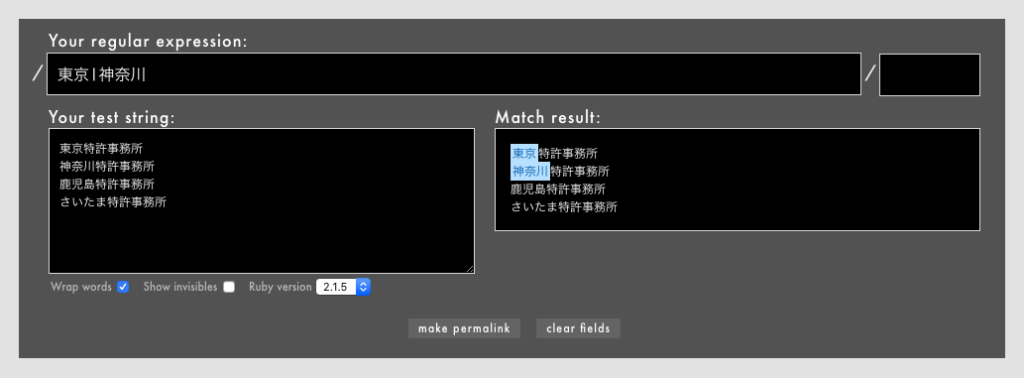
なお、(東京|神奈川|鹿児島|東京)のようにマッチする項目が(|||)に複数ある場合は、最も左側のパターンが採用されますのでご注意下さい。(|||)の中にさらに細かく正規表現を書く場合に、これをうまく利用することもできます。
|も有用なメタ文字です。複雑な正規表現でも|で上手に分割すると書きやすさ読みやすさが向上することもあります(Rubular)。無理して正規表現を一発で決めようとするより、|で分割できるかどうかを検討しましょう。
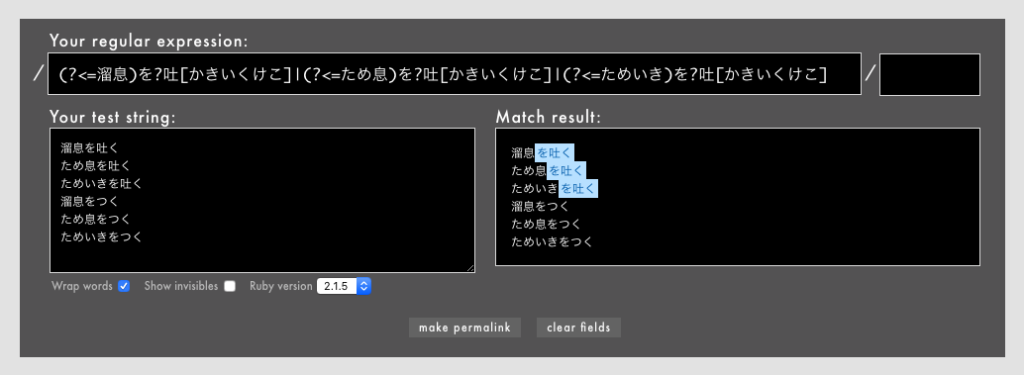
注: 上の例では今回解説しなかった正規表現(
(?<=))が使われています。
⚓ |の注意
|は有用ですが、以下のような点を見落としがちなのでご注意ください。
⚓ (||)に+を追加する場合は注意
たとえば/(引き|抜き)にくい/とすると、「引きにくい」「抜きにくい」にはマッチするが「引き抜きにくい」にはマッチしません(Rubular)。
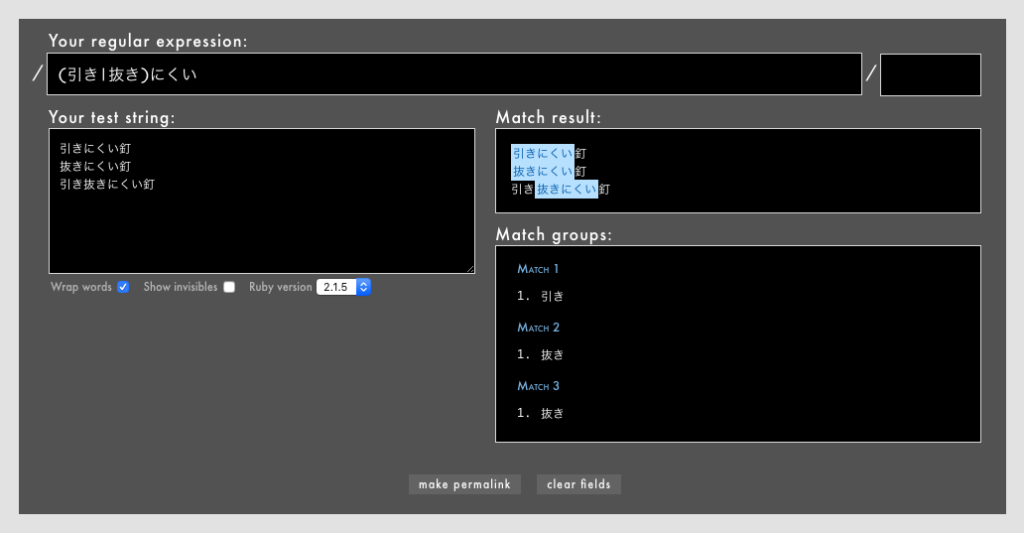
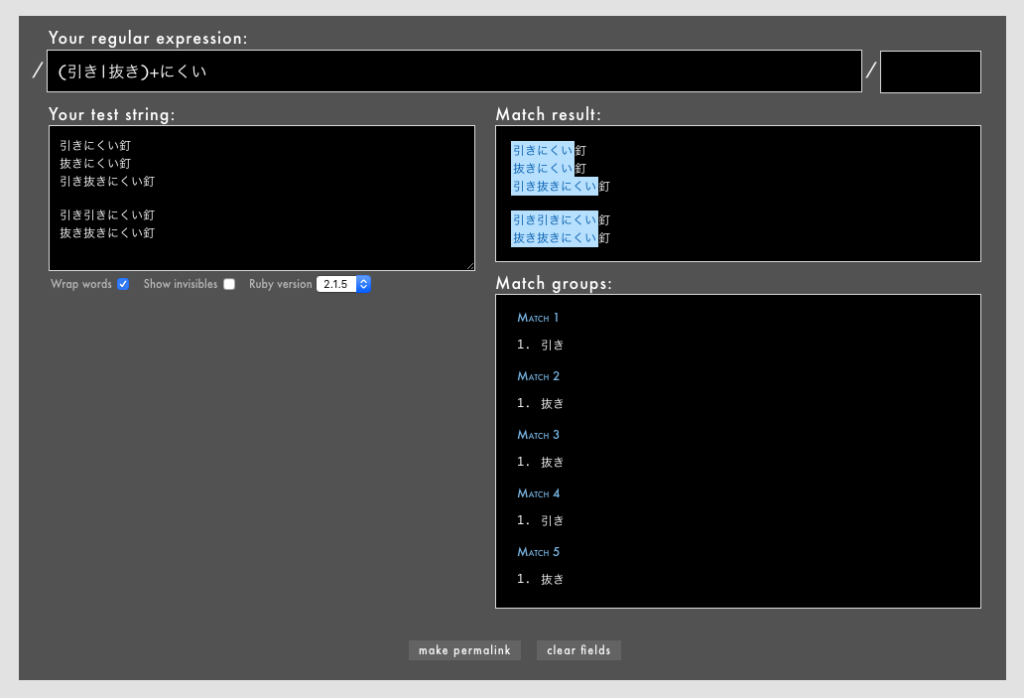
こういう場合、/(引き|抜き)+にくい/とすれば「引き抜きにくい」にもマッチしますが、今度は「引き引きにくい」や「抜き抜きにくい」にもマッチしてしまいます!(Rubular)。
もっと言うと、「抜き引きにくい」や「抜き引き引き抜き抜きにくい」...などにもマッチしてしまいます。
現実の日本語にはまず出現しませんが、欲しくないマッチであることには変わりありません。
これは、たとえばパターンをフレーズにして|で全体を並列する方法で回避できます(Rubular)。
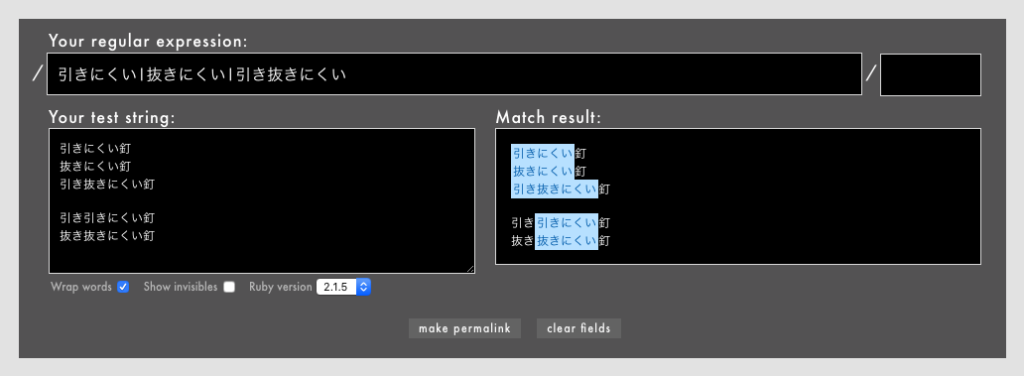
「引き引きにくい」や「抜き抜きにくい」に部分マッチしているのを排除したい場合については、今後扱います。
⚓ |を余分に付けてしまう事故
()の中に|で文字列を列挙するときに、つい末尾に余分な|を置いてしまいがちです。なまじ意図しているマッチは正常に動いてしまうので案外見落とされやすいバグです。
- 例: /
(A|B|C)/と書くつもりが/(A|B|C|)/になっていた(Rubular)
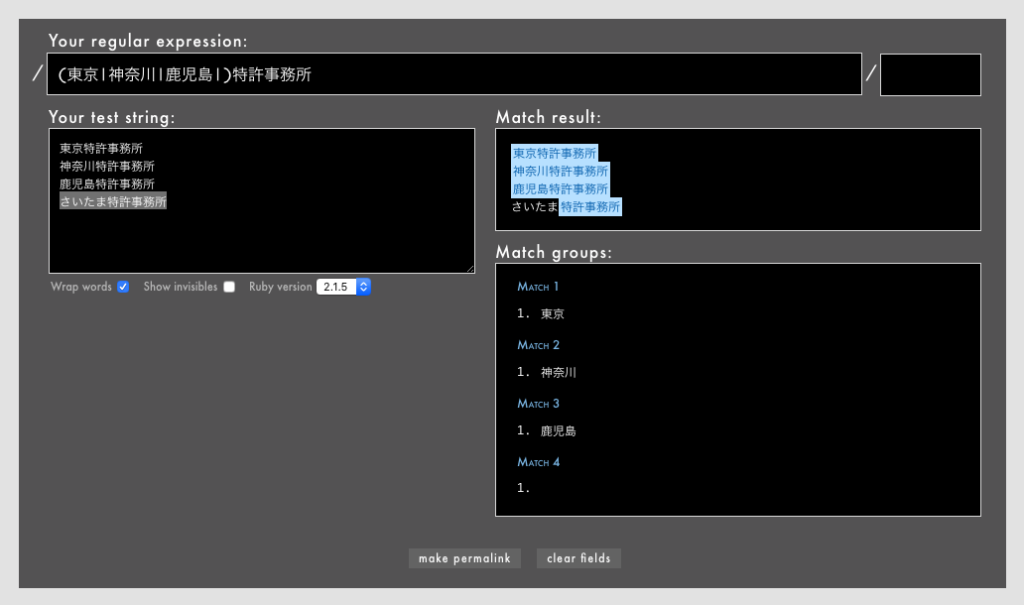
マッチさせるつもりのなかった「さいたま特許事務所」にまで部分マッチしてしまいました。
さらに、|の列挙が()で囲まれていないとより深刻です(Rubular)。
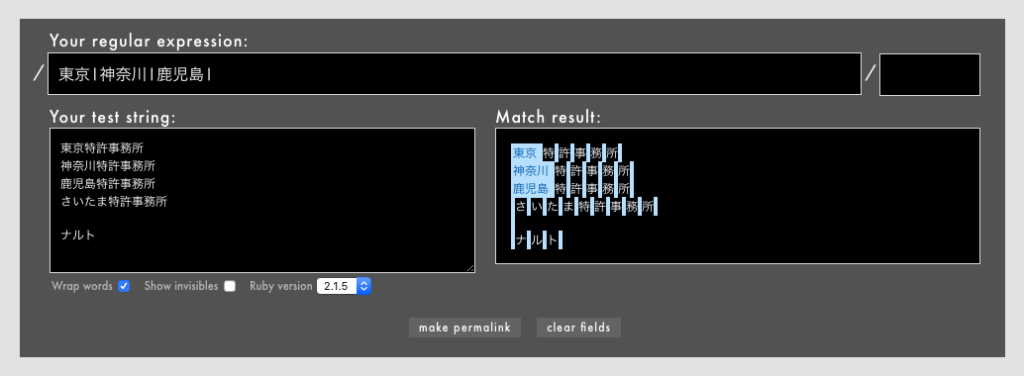
上は「文字ではない部分」、つまり文字と文字の間にまでマッチしてしまいました。実は直前の「さいたま特許事務所」も、「さいたま」と「特許事務所」の間がマッチに含まれているのです。
⚓ 部分マッチのワナ
詳しくは以下の記事をご覧ください。
今回は正規表現の基本的な8つのメタ文字と利用法をご紹介しました。次回にご期待ください。
- 1: 基本となる8つの正規表現(本記事)
- 2: 正規表現とは何か/ワイルドカードとの違い
- 3: 冒頭/末尾にマッチするメタ文字とセキュリティ、文字セットの否定と範囲
- 4: 先読みと後読みを極める
- 5(特別編)
|と部分マッチのワナ - 6: 文字セットのショートハンド
- 7: Unicode文字ポイントとUnicode文字クラス
- 8: 対象の構造を意識した「適度にDRYな」書き方
- 9:
.*や.+がバックトラックで不利な理由 - 10: 危険な「Catastrophic Backtracking」前編